
Automatisk taligenkänning (ASR) har kommit långt. Även om det uppfanns för länge sedan, användes det nästan aldrig av någon. Men tid och teknik har nu förändrats avsevärt. Ljudtranskription har utvecklats avsevärt.
Teknologier som AI (artificiell intelligens) har drivit processen för översättning av ljud till text för snabba och exakta resultat. Som ett resultat har dess applikationer i den verkliga världen också ökat, med några populära appar som Tik Tok, Spotify och Zoom som bäddar in processen i sina mobilappar.
Så låt oss utforska ASR och upptäcka varför det är en av de mest populära teknikerna 2022.
Vad är tal till text?
Tal till text är en AI-förbättrad teknik som översätter mänskligt tal från en analog till en digital form. Vidare transkriberas den digitala formen av den insamlade datan till ett textformat.
Tal till text förväxlas ofta med röstigenkänning som skiljer sig helt från denna metod. Inom röstigenkänning ligger fokus på att identifiera röstmönster hos människor, medan systemet i denna metod försöker identifiera de ord som talas.
Vanliga namn på tal till text
Denna avancerade taligenkänningsteknik är också populär och hänvisas till med följande namn:
- Automatisk taligenkänning (ASR)
- Taligenkänning
- Datortaligenkänning
- Ljudtranskription
- Skärmläsning
Förstå hur automatisk taligenkänning fungerar
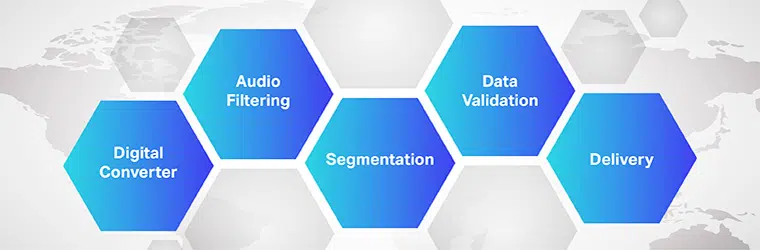
Arbetet med programvara för översättning av ljud-till-text är komplex och involverar implementering av flera steg. Som vi vet är speech-to-text en exklusiv programvara utformad för att konvertera ljudfiler till ett redigerbart textformat; det gör det genom att utnyttja röstigenkänning.
Behandla
- Inledningsvis, med hjälp av en analog-till-digital-omvandlare, tillämpar ett datorprogram språkliga algoritmer på de tillhandahållna data för att skilja vibrationer från hörselsignaler.
- Därefter filtreras de relevanta ljuden genom att mäta ljudvågorna.
- Vidare fördelas/segmenteras ljuden i hundradelar eller tusendelar av sekunder och matchas mot fonem (En mätbar ljudenhet för att skilja ett ord från ett annat).
- Fonemen körs vidare genom en matematisk modell för att jämföra befintlig data med välkända ord, meningar och fraser.
- Utdata finns i en text- eller datorbaserad ljudfil.
[Läs även: En omfattande översikt över automatisk taligenkänning]

Vad är användningen av tal till text?
Det finns flera användningsområden för automatisk taligenkänning, som t.ex
- Innehållssökning: De flesta av oss har gått från att skriva bokstäver på våra telefoner till att trycka på en knapp för att programvaran ska känna igen vår röst och ge önskat resultat.
- Kundservice: Chatbots och AI-assistenter som kan guida kunderna genom de få inledande stegen i processen har blivit vanliga.
- Dold bildtext i realtid: Med ökad global tillgång till innehåll har textning i realtid blivit en framträdande och betydelsefull marknad, vilket driver ASR framåt för dess användning.
- Elektronisk dokumentation: Flera administrationsavdelningar har börjat använda ASR för att uppfylla dokumentationssyfte, vilket ger bättre hastighet och effektivitet.
Vilka är de viktigaste utmaningarna för taligenkänning?
Ljudkommentar har ännu inte nått toppen av sin utveckling. Det finns fortfarande många utmaningar som ingenjörerna försöker motverka för att göra systemet effektivt, som t.ex
- Få kontroll över accenter och dialekter.
- Förstå sammanhanget för de talade meningarna.
- Separation av bakgrundsljud för att förstärka ingångskvaliteten.
- Växla koden till olika språk för effektiv bearbetning.
- Analysera de visuella ledtrådarna som används i talet när det gäller videofiler.
Ljudtranskriptioner och utveckling av tal-till-text AI
Den största utmaningen med programvaran Automatic Speech Recognition är att skapa dess utdata 100 % exakt. Eftersom rådata är dynamiska och en enda algoritm inte kan tillämpas, annoteras data för att träna AI:n att förstå den i rätt sammanhang.
För att utföra denna process måste specifika uppgifter implementeras, såsom:
 Named Entity Recognition (NER): NER är processen att identifiera och segmentera olika namngivna enheter i specifika kategorier.
Named Entity Recognition (NER): NER är processen att identifiera och segmentera olika namngivna enheter i specifika kategorier.- Sentiment & ämnesanalys: Programvaran som använder flera algoritmer genomför sentimentanalysen av de tillhandahållna data för att ge felfria resultat.
 Named Entity Recognition (NER):
Named Entity Recognition (NER): - Avsikts- och konversationsanalys: Avsiktsdetektering syftar till att träna AI:n att känna igen talarens avsikt. Den används främst för att skapa AI-drivna chatbots.
Slutsats
Tal-till-text-tekniken befinner sig i ett bra skede just nu. Med fler digitala enheter som inkluderar röstsökning och kontrollassistenter i sina appar, kommer efterfrågan på ljudtranskription att öka. Om du är sugen på att lägga till denna imponerande funktion till din app, kontakta Shaips experter för insamling av taldata för att få alla detaljer.


