
Robust träningsdataplattform
ShaipCloud™ använder patenterad teknologi för att samla in, spåra och övervaka arbetsbelastningar, transkribera ljud och yttranden, kommentera text, bild och video, samt hantera kvalitetskontroll och datautbyte. Resultatet? Ditt AI-projekt får data av högsta möjliga kvalitet. Inte bara får du det snabbt och till en överkomlig kostnad, utan när ditt AI-projekt växer växer ShaipCloud™ med det genom skalbarhet och plattformsintegrationer som krävs för att göra ditt jobb enklare och leverera framgångsrika resultat.

Plattformen förenklar arbetsflödet, minskar friktionen i att arbeta med en distribuerad global arbetsstyrka, ger större synlighet och kvalitetskontroll i realtid. Det finns dataplattformar. Sedan finns det AI-dataplattformar. Vi är de sistnämnda eftersom den säkra ShaipCloud™ human-in-the-loop-plattformen erbjuder oöverträffad funktionalitet och hastighet för att samla in, transformera och kommentera stora mängder data (text, ljud, bilder och video) för att träna och förbättra AI och ML-algoritmer för användningsfall för NLP och Computer Vision.





Bildsamling
Skapa data skräddarsydd för alla domäner och användningsfall genom vårt omfattande nätverk av världsomspännande ämnesexperter. Vi erbjuder olika bilddataset från flera regioner. Utnyttja vår AI-gemenskap för att få tillgång till tusentals bilder från länder över hela världen.

Bildanmärkning
Vi erbjuder ett brett urval av anteckningsstilar, som omfattar 2D- och 3D-begränsningsrutor, polygonkommentarer, landmärkesidentifiering och semantisk segmentering.

Videosamling
Skaffa eller producera videodata som är skräddarsydda för alla domäner och användningsfall genom vårt omfattande nätverk av världsomspännande ämnesexperter. Vi erbjuder olika, skådespelarbaserade videoscenarier på flera språk för att stödja dina projekt och täcker ett brett spektrum av situationer.

Videonotering
Kommentera videor på ett effektivt och korrekt sätt bild-för-bildruta med tidsstämplar. Använd våra videotranskriptionstjänster för att omvandla ljud till text, förbättra sökförmågan och tillgängligheten för SEO-ändamål.

Insamling av taldata
Samla in olika data av högsta kvalitet på mer än 150 språk och dialekter, som omfattar ett brett spektrum av demografi, såsom kön och ålder. Vår data täcker olika talaregenskaper, dialogtyper – inklusive monologer, konversationer med dubbla högtalare och flera högtalare, såväl som manus och spontant tal. Vi tillhandahåller även data från en mängd olika miljöer, såsom hem, restauranger, callcenter, fordon och studioinspelningar, som täcker ett brett spektrum av scenarier.
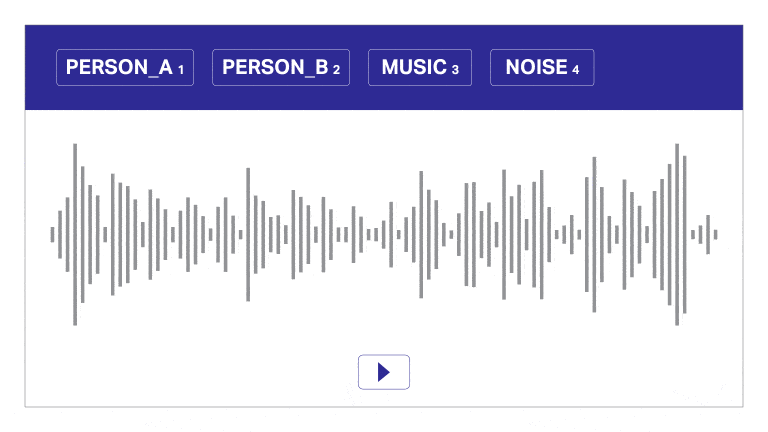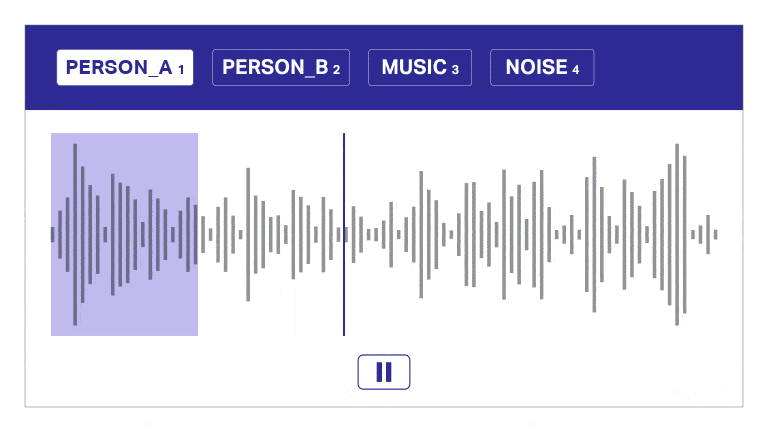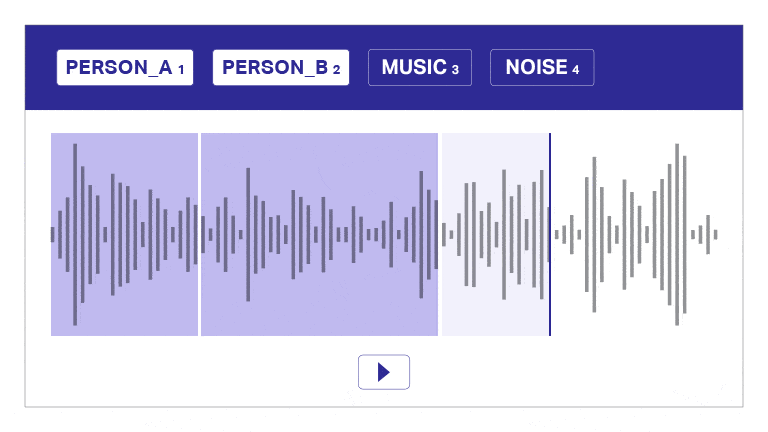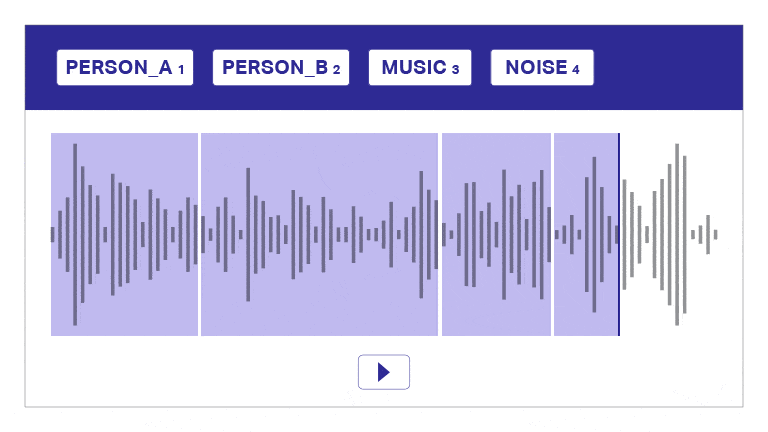
Taldataanteckning
Vårt annoterings- och transkriptionsverktyg segmenterar automatiskt ljud i lager, skiljer mellan högtalare och ger tidsstämplar för effektiv ljudkommentar. Detta användarvänliga verktyg möjliggör snabb och exakt transkription och tidsstämpling, vilket möjliggör korrekta anteckningar i skala.

Insamling av textdata
Förbättra dina AI-modeller och stärk deras anpassningsförmåga genom att använda högkvalitativ, varierad text- och dokumentdata i ett brett utbud av språk och format, allt från kvitton och onlinenyhetsartiklar till chatbots avsikter och yttranden.

Textdataanteckning
Våra verktyg för textkommentarer förenklar processen med att kommentera text på djupet, vilket gör att dina modeller kan förstå text och extrahera värdefulla insikter. Dessutom tillhandahåller vi tjänster för Named Entity Extraction och Entity Linking för att ytterligare förbättra dina textanalysmöjligheter.




