


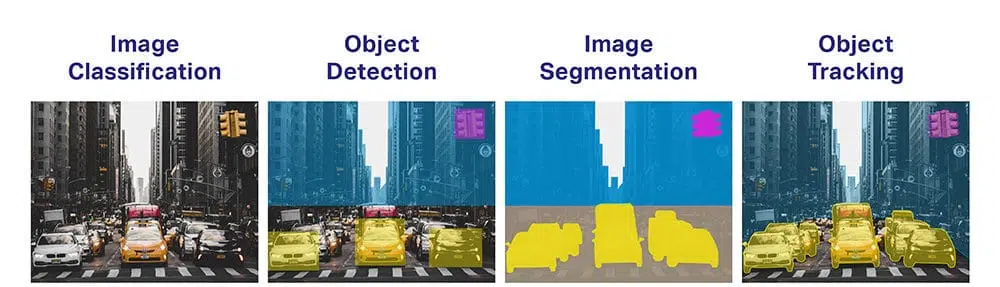
- Objektklassificering: Vilken bred kategori av objekt finns det?
- Objektidentifiering: Vilken typ av ett visst objekt finns det?
- Objektverifiering: Vilket är objektet på fotografiet?
- Objektdetektering: Var är objekten på fotografiet?
- Objekt Landmark Detection: Vilka är de viktigaste punkterna för objektet på fotografiet?
- Objekt segmentering: Vilka pixlar tillhör objektet i bilden?
- Objektigenkänning: Vilka föremål finns på det här fotografiet och var är de?

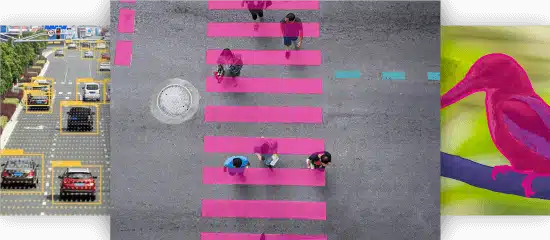


Bildsamling

Videosamling

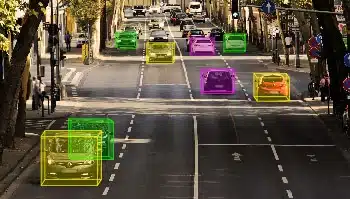
Avgränsande lådor
3D Cuboids
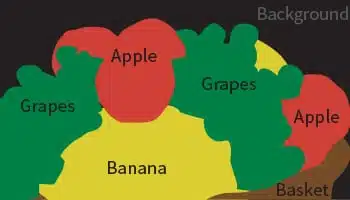
Semantisk segmentering

Anteckning om polygon

Landmärkesannotering

Linjesegmentering

Bildtranskription
Video Transkription

Bildklassificering
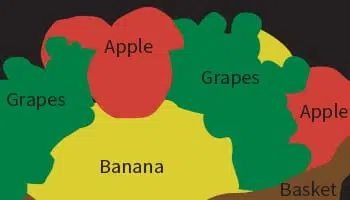
Bildsegmentering

Kommentar om bildtangentpunkt

Videoklassificering
Videosegmentering

- Användningsfall: ADAS-modell i bilen
- Format: Bilder
- Volym: 455,000+
- Anteckning: Nej

- Användningsfall: Landmärke Detektion
- Format: Bilder
- Volym: 80,000+
- Anteckning: Nej

- Användningsfall: Spårning av fotgängare
- Format: Video
- Volym: 84,500+
- Anteckning: Ja

- Användningsfall: Matigenkänning
- Format: Bilder
- Volym: 55,000+
- Anteckning: Ja

Sjukvård AI
Träna ML-modeller för att upptäcka cancermull i hudbilder eller hitta symtom i MR-skanningar eller patientens röntgen.

ansiktsigenkänning
Träna ML-modeller för att identifiera bilder av människor baserat på ansiktsdrag och jämföra dem med en databas med ansiktsprofiler för att upptäcka och märka människor.

Geospatiala applikationer
Annotering av satellitbilder och UAV -fotografering för att förbereda datamängder för geoprocessering och kommentera 3D -punktmoln för Geo.AI.

Augmented Reality
Med AR-headset placerar du virtuella objekt i den verkliga världen. Det kan upptäcka plana ytor som väggar, bordsskivor och golv - en mycket viktig del i att skapa djup och dimensioner och placera virtuella föremål i den fysiska världen.

Självkörande bilar
Flera kameror spelar in videor från en annan vinkel för att identifiera gränserna för trafiksignaler, vägar, bilar, föremål och fotgängare i närheten för att träna självkörande bilar för att automatiskt styra fordonet och undvika att träffa hinder när du kör passageraren säkert.

Detaljhandel / e-handel
Med datorsyn i detaljhandeln kan applikationerna erbjuda personliga rekommendationer baserade på kunder som köper mönster och påskyndar affärsverksamheten som hyllhantering, betalningar etc.




Personer
Dedikerade och utbildade team:
- 30,000+ medarbetare för dataskapande, märkning och kvalitetssäkring
- Godkänd projektledningsteam
- Erfaren produktutvecklingsteam
- Talent Pool Sourcing & Onboarding Team

Behandla
Högsta processeffektivitet säkerställs med:
- Robust 6 Sigma Stage-Gate-process
- Ett dedikerat team med 6 Sigma-svarta bälten - Viktiga processägare och kvalitetskrav
- Kontinuerlig förbättring och återkopplingsslinga

plattform
Den patenterade plattformen erbjuder fördelar:
- Webbaserad end-to-end-plattform
- Oklanderlig kvalitet
- Snabbare TAT
- Sömlös leverans
Personer
Dedikerade och utbildade team:
- 30,000+ medarbetare för dataskapande, märkning och kvalitetssäkring
- Godkänd projektledningsteam
- Erfaren produktutvecklingsteam
- Talent Pool Sourcing & Onboarding Team
Behandla
Högsta processeffektivitet säkerställs med:
- Robust 6 Sigma Stage-Gate-process
- Ett dedikerat team med 6 Sigma-svarta bälten - Viktiga processägare och kvalitetskrav
- Kontinuerlig förbättring och återkopplingsslinga
plattform
Den patenterade plattformen erbjuder fördelar:
- Webbaserad end-to-end-plattform
- Oklanderlig kvalitet
- Snabbare TAT
- Sömlös leverans