Beskrivning
 Artificiell intelligens handlar om att använda maskiner för att lyfta människors liv och livsstil genom att göra deras vardagliga liv intressanta och överflödiga uppgifter enkla. AI är aldrig tänkt att vara en dominerande kraft utan en komplementär sådan som arbetar tillsammans med människor för att lösa det osannolika och bana väg för kollektiv evolution.
Artificiell intelligens handlar om att använda maskiner för att lyfta människors liv och livsstil genom att göra deras vardagliga liv intressanta och överflödiga uppgifter enkla. AI är aldrig tänkt att vara en dominerande kraft utan en komplementär sådan som arbetar tillsammans med människor för att lösa det osannolika och bana väg för kollektiv evolution.
Från och med nu går vi på rätt väg med betydande genombrott som sker över branscher med hjälp av AI. Om du till exempel tar vård, hjälper AI-system tillsammans med maskininlärningsmodeller experter att bättre förstå cancer och komma på behandlingar för den. Neurologiska störningar och problem som PTSD behandlas med hjälp av AI. Vacciner utvecklas i snabb takt tack vare AI-drivna kliniska prövningar och simuleringar.
Inte bara sjukvården, varje enskild bransch eller segment som AI berör revolutioneras. Autonoma fordon, smarta närbutiker, wearables som FitBit och till och med våra smartphonekameror kan ta bättre bilder av våra ansikten med AI.
Tack vare de innovationer som sker inom AI-utrymmet, tränger företag in i spektrumet med olika användningsfall och lösningar. På grund av detta förväntas den globala AI-marknaden nå ett marknadsvärde på cirka 267 miljarder USD i slutet av 2027. Dessutom implementerar cirka 37 % av företagen där ute redan AI-lösningar i sina processer och produkter.
Mer intressant är att nära 77 % av de produkter och tjänster vi använder idag drivs av AI. Med det tekniska konceptet som ökar avsevärt över vertikaler, hur lyckas företag göra omöjligt med AI?

 Hur förutsäger enheter så enkla som en klocka hjärtinfarkt hos människor exakt? Hur är det möjligt att bilar och bilar som alltid har krävt en förare plötsligt blir mindre förare på vägarna?
Hur förutsäger enheter så enkla som en klocka hjärtinfarkt hos människor exakt? Hur är det möjligt att bilar och bilar som alltid har krävt en förare plötsligt blir mindre förare på vägarna?
Hur får chatbots oss att tro att vi pratar med en annan människa på andra sidan?
Om du observerar svaret på varje fråga, kokar det ner till bara ett element – DATA. Data står i centrum för alla AI-specifika operationer och processer. Det är data som hjälper maskiner att förstå koncept, bearbeta input och leverera korrekta resultat.
Alla stora AI-lösningar som finns där ute är alla produkter av en avgörande process som vi kallar datainsamling eller datainsamling eller AI-träningsdata.
Den här omfattande guiden handlar om att hjälpa dig förstå vad det är och varför det är viktigt.
Vad är AI-datainsamling?
Maskiner har inget eget sinne. Frånvaron av detta abstrakta koncept gör att de saknar åsikter, fakta och förmågor som resonemang, kognition med mera. De är bara orörliga lådor eller enheter som tar plats. För att förvandla dem till kraftfulla medier behöver du algoritmer och ännu viktigare data.
 Algoritmerna som utvecklas behöver något att arbeta med och bearbeta och att något är data som är relevant, kontextuell och aktuell. Processen att samla in sådan data för maskiner för att tjäna sina avsedda syften kallas AI-datainsamling.
Algoritmerna som utvecklas behöver något att arbeta med och bearbeta och att något är data som är relevant, kontextuell och aktuell. Processen att samla in sådan data för maskiner för att tjäna sina avsedda syften kallas AI-datainsamling.
Varje enskild AI-aktiverad produkt eller lösning vi använder idag och resultaten de erbjuder härrör från år av utbildning, utveckling och optimering. Från enheter som erbjuder navigeringsvägar till de komplexa system som förutsäger utrustningsfel dagar i förväg, varje enskild enhet har gått igenom år av AI-träning för att kunna leverera exakta resultat.
AI-datainsamling är det preliminära steget i AI-utvecklingsprocessen som redan från början avgör hur effektivt ett AI-system skulle vara. Det är processen att hämta relevanta datauppsättningar från en mängd källor som hjälper AI-modeller att bearbeta detaljer bättre och få fram meningsfulla resultat.




Hur samlar man in data för en maskininlärning?
 Det är här det börjar bli lite knepigt. Från början verkar det som att du har en lösning på ett verkligt problem i åtanke, du vet att AI skulle vara det perfekta sättet att gå tillväga och du har utvecklat dina modeller. Men nu är du i den avgörande fasen där du måste påbörja dina AI-träningsprocesser. Du behöver rikligt med AI-träningsdata för att få dina modeller att lära sig koncept och leverera resultat. Du behöver också valideringsdata för att testa dina resultat och optimera dina algoritmer.
Det är här det börjar bli lite knepigt. Från början verkar det som att du har en lösning på ett verkligt problem i åtanke, du vet att AI skulle vara det perfekta sättet att gå tillväga och du har utvecklat dina modeller. Men nu är du i den avgörande fasen där du måste påbörja dina AI-träningsprocesser. Du behöver rikligt med AI-träningsdata för att få dina modeller att lära sig koncept och leverera resultat. Du behöver också valideringsdata för att testa dina resultat och optimera dina algoritmer.
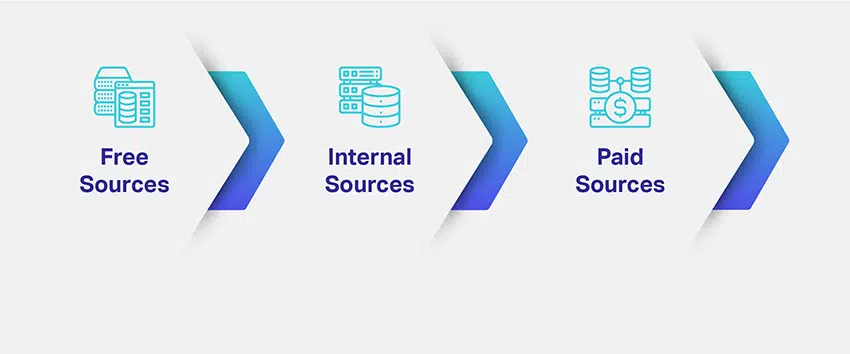
Så, hur hämtar du din data? Vilken data behöver du och hur mycket av den? Vilka är de flera källorna för att hämta relevant data?
Företag bedömer nisch och syfte med sina ML-modeller och kartlägger möjliga sätt att hämta relevanta datauppsättningar. Att definiera vilken datatyp som behövs löser en stor del av ditt problem med datakällan. För att ge dig en bättre uppfattning finns det olika kanaler, vägar, källor eller medier för datainsamling:
Hur påverkar dålig data dina AI-ambitioner?
Vi listade de tre vanligaste dataresurserna av den anledningen att du kommer att ha en idé om hur du ska närma dig datainsamling och inköp. Men vid denna tidpunkt blir det viktigt att också förstå att ditt beslut alltid kan avgöra ödet för din AI-lösning.
I likhet med hur högkvalitativ AI-träningsdata kan hjälpa din modell att leverera korrekta och aktuella resultat, kan dålig träningsdata också bryta dina AI-modeller, förvränga resultat, införa fördomar och ge andra oönskade konsekvenser.
Men varför händer detta? Är det inte meningen att någon data ska träna och optimera din AI-modell? Ärligt talat, nej. Låt oss förstå detta ytterligare.
Dålig data – vad är det?
 Dålig data är all data som är irrelevant, felaktig, ofullständig eller partisk. Tack vare dåligt definierade datainsamlingsstrategier kan de flesta dataforskare och anteckningsexperter tvingas arbeta med dålig data.
Dålig data är all data som är irrelevant, felaktig, ofullständig eller partisk. Tack vare dåligt definierade datainsamlingsstrategier kan de flesta dataforskare och anteckningsexperter tvingas arbeta med dålig data.
Skillnaden mellan ostrukturerad och dålig data är att insikter i ostrukturerad data finns överallt. Men i huvudsak kan de vara användbara oavsett. Genom att spendera ytterligare tid skulle datavetare fortfarande kunna extrahera relevant information från ostrukturerade datamängder. Det är dock inte fallet med dålig data. Dessa datauppsättningar innehåller inga/begränsade insikter eller information som är värdefull eller relevant för ditt AI-projekt eller dess utbildningsändamål.
Så när du hämtar dina datamängder från gratisresurser eller har löst etablerade interna datakontaktpunkter, är chansen stor att du laddar ner eller genererar dålig data. När dina forskare arbetar med dålig data slösar du inte bara bort mänskliga timmar utan driver även lanseringen av din produkt.
Om du fortfarande är osäker på vad dålig data kan göra med dina ambitioner, här är en snabb lista:
- Du spenderar otaliga timmar på att anskaffa dålig data och slösar timmar, ansträngning och pengar på resurser.
- Dålig data kan ge dig juridiska problem, om du inte märker det och kan sänka effektiviteten hos din AI
modeller. - När du tar din produkt tränad på dålig data live påverkar det användarupplevelsen
- Dåliga data kan göra resultat och slutsatser partiska, vilket kan ge ytterligare bakslag.
Så om du undrar om det finns en lösning på detta så finns det faktiskt.
AI Training Dataleverantörer till undsättning
 En av de grundläggande lösningarna är att välja en dataleverantör (betalda källor). Leverantörer av AI-utbildningsdata säkerställer att det du får är korrekt och relevant och att du får datauppsättningar levererade till dig i en strukturerad form. Du behöver inte vara inblandad i besväret med att flytta från portal till portal på jakt efter datauppsättningar.
En av de grundläggande lösningarna är att välja en dataleverantör (betalda källor). Leverantörer av AI-utbildningsdata säkerställer att det du får är korrekt och relevant och att du får datauppsättningar levererade till dig i en strukturerad form. Du behöver inte vara inblandad i besväret med att flytta från portal till portal på jakt efter datauppsättningar.
Allt du behöver göra är att ta in data och träna dina AI-modeller för perfektion. Med det sagt är vi säkra på att din nästa fråga handlar om kostnaderna för att samarbeta med dataleverantörer. Vi förstår att några av er redan arbetar med en mental budget och det är precis dit vi är på väg härnäst.
Faktorer att tänka på när du tar fram en effektiv budget för ditt datainsamlingsprojekt
AI-utbildning är ett systematiskt tillvägagångssätt och det är därför budgetering blir en integrerad del av det. Faktorer som avkastning på investeringen, exakta resultat, utbildningsmetoder och mer bör övervägas innan man investerar en enorm summa pengar i AI-utveckling. Många projektledare eller företagare fumlar i detta skede. De fattar förhastade beslut som leder till oåterkalleliga förändringar i deras produktutvecklingsprocess, vilket i slutändan tvingar dem att spendera mer.
Men det här avsnittet ger dig rätt insikter. När du sätter dig ner för att arbeta med budgeten för AI-träning är tre saker eller faktorer oundvikliga.

Låt oss titta på var och en i detalj.
Mängden data du behöver
Vi har hela tiden sagt att effektiviteten och noggrannheten hos din AI-modell beror på hur mycket den är tränad. Detta innebär att ju mer volymen av datamängder, desto mer lärande. Men detta är väldigt vagt. För att sätta en siffra på denna uppfattning publicerade Dimensional Research en rapport som avslöjade att företag behöver minst 100,000 XNUMX exempeldataset för att träna sina AI-modeller.
Med 100,000 100,000 datamängder menar vi XNUMX XNUMX kvalitativa och relevanta datamängder. Dessa datauppsättningar bör ha alla väsentliga attribut, kommentarer och insikter som krävs för att dina algoritmer och maskininlärningsmodeller ska kunna bearbeta information och utföra avsedda uppgifter.
Med detta är en allmän tumregel, låt oss ytterligare förstå att mängden data du behöver också beror på en annan intrikat faktor som är ditt företags användningsfall. Vad du tänker göra med din produkt eller lösning avgör också hur mycket data du behöver. Till exempel skulle ett företag som bygger en rekommendationsmotor ha andra datavolymkrav än ett företag som bygger en chatbot.
Dataprisstrategi
När du är klar med att slutföra hur mycket data du faktiskt behöver måste du nästa gång arbeta med en dataprisstrategi. Detta betyder i enkla termer hur du skulle betala för de datauppsättningar du skaffar eller genererar.
I allmänhet är dessa de konventionella prissättningsstrategier som följs på marknaden:
| Data typ | Prissättningsstrategi |
|---|---|
| Pris per enskild bildfil | |
| Pris per sekund, minut, timme eller individuell bildruta | |
| Pris per sekund, en minut eller timme | |
| Pris per ord eller mening |
Men vänta. Detta är återigen en tumregel. Den faktiska kostnaden för att skaffa datamängder beror också på faktorer som:
- Det unika marknadssegmentet, demografi eller geografi där datauppsättningar måste hämtas
- Det invecklade i ditt användningsfall
- Hur mycket data behöver du?
- Din tid att marknadsföra
- Eventuella skräddarsydda krav och mer
Om du observerar kommer du att veta att kostnaden för att skaffa bulkkvantiteter av bilder för ditt AI-projekt kan vara mindre, men om du har för många specifikationer kan priserna skjuta upp.
Dina inköpsstrategier
Det här är knepigt. Som du såg finns det olika sätt att generera eller hämta data för dina AI-modeller. Sunt förnuft skulle diktera att gratisresurser är de bästa eftersom du kan ladda ner nödvändiga mängder datauppsättningar gratis utan några komplikationer.
Just nu verkar det också som att betalda källor är för dyra. Men det är här som ett lager av komplikationer tillkommer. När du skaffar datauppsättningar från kostnadsfria resurser spenderar du extra tid och ansträngning på att rengöra dina datauppsättningar, kompilera dem till ditt företagsspecifika format och sedan kommentera dem individuellt. Du ådrar dig driftskostnader i processen.
Med betalda källor är betalningen engångsbetalning och du får även maskinklara datamängder i handen vid den tidpunkt du behöver. Kostnadseffektiviteten är mycket subjektiv här. Om du känner att du har råd att lägga tid på att kommentera gratis datauppsättningar kan du budgetera därefter. Och om du tror att din konkurrens är hård och med begränsad tid till marknaden kan du skapa en krusningseffekt på marknaden, du bör föredra betalda källor.
Budgetering handlar om att bryta ner detaljerna och tydligt definiera varje fragment. Dessa tre faktorer bör tjäna dig som en färdplan för din budgeteringsprocess för AI-träning i framtiden.
Sparar du på utgifter med intern datainsamling?
 Under budgeteringen undersökte vi hur gratis resurser tvingar dig att spendera mer på längre sikt. Vid den tidpunkten skulle du automatiskt ha undrat över kostnadseffektiviteten i den interna datainsamlingsprocessen.
Under budgeteringen undersökte vi hur gratis resurser tvingar dig att spendera mer på längre sikt. Vid den tidpunkten skulle du automatiskt ha undrat över kostnadseffektiviteten i den interna datainsamlingsprocessen.
Vi vet att du fortfarande är tveksam till betalda källor och det är därför det här avsnittet kommer att rensa din skepsis mot det och belysa de dolda kostnaderna för intern datagenerering.
Är intern datainsamling dyrt?
Ja det är det!
Nu, här är ett utförligt svar. Kostnad är allt du spenderar. Medan vi diskuterade gratis resurser avslöjade vi att du spenderar pengar, tid och ansträngning i processen. Detta gäller även för in-house datainsamling.
 På grund av det faktum att du har specialdefinierade beröringspunkter eller datakanaler, betyder det inte att du skulle ha det maskinklara datamängder i slutet. Datan du genererar kommer fortfarande att vara mestadels rå och ostrukturerad. Du kanske har all information du behöver på ett ställe, men vad informationen innehåller kommer att finnas överallt.
På grund av det faktum att du har specialdefinierade beröringspunkter eller datakanaler, betyder det inte att du skulle ha det maskinklara datamängder i slutet. Datan du genererar kommer fortfarande att vara mestadels rå och ostrukturerad. Du kanske har all information du behöver på ett ställe, men vad informationen innehåller kommer att finnas överallt.
I slutändan skulle du sluta spendera på att betala dina anställda, datavetare, annotatorer, kvalitetssäkringspersonal och mer. Du kommer också att spendera på prenumerationer på annoteringsverktyg och
underhåll av CMS, CRM och andra infrastrukturkostnader.
Dessutom är datauppsättningar skyldiga att ha bias och noggrannhetsproblem, vilket du behöver för att manuellt få dem sorterade. Och om du har ett avgångsproblem i ditt AI-träningsdatateam måste du spendera på att rekrytera nya medlemmar, orientera dem om dina processer, träna dem att använda dina verktyg och mer.
Du kommer att sluta spendera mer än vad du till slut skulle tjäna på längre sikt. Det tillkommer även anteckningskostnader. Vid varje given tidpunkt är den totala kostnaden för att arbeta med intern data:
Kostnad som uppstått = antal annotatorer * Kostnad per annotator + plattformskostnad
Om din AI-träningskalender är schemalagd för månader, föreställ dig vilka utgifter du konsekvent skulle ådra dig. Så, är detta den idealiska lösningen för datainsamlingsproblem eller finns det något alternativ?
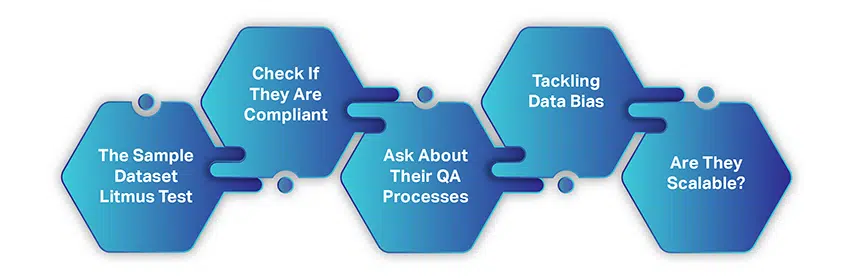
Hur man väljer rätt AI Data Collection Company
Att välja ett AI-datainsamlingsföretag är inte lika komplicerat eller tidskrävande som att samla in data från kostnadsfria resurser. Det finns bara några enkla faktorer du behöver tänka på och sedan skaka hand för ett samarbete.
När du börjar leta efter en dataleverantör antar vi att du har följt och övervägt vad vi än har diskuterat hittills. Men här är en snabb sammanfattning:
- Du har ett väldefinierat användningsfall i åtanke
- Ditt marknadssegment och datakrav är tydligt fastställda
- Din budgetering är på plats
- Och du har en uppfattning om mängden data du behöver
Med dessa objekt avmarkerade, låt oss förstå hur du kan leta efter en idealisk leverantör av utbildningsdatatjänster.