
Beskrivning
Den här guiden kommer att vara extremt hjälpsam för de köpare och beslutsfattare som börjar vända sina tankar mot muttrar och bultar för datainsamling och dataimplementering både för neurala nätverk och andra typer av AI- och ML-operationer.

Denna artikel är helt dedikerad till att belysa vad processen är, varför den är oundviklig, avgörande
faktorer som företag bör tänka på när de närmar sig dataannotationsverktyg och mer. Så, om du äger ett företag, gör dig redo för att bli upplyst, eftersom den här guiden leder dig genom allt du behöver veta om datakommentarer.
Låt oss börja.
För er som läser igenom artikeln, här är några snabba takeaways som du hittar i guiden:
- Förstå vad datanotering är
- Lär känna de olika typerna av dataanmärkningsprocesser
- Känn fördelarna med att implementera dataanmälningsprocessen
- Få klarhet i om du ska gå på intern datamärkning eller få dem outsourcade
- Insikter om att välja rätt dataanmärkning också
Vad är maskininlärning?
 Vi har pratat om hur dataannotering eller datamärkning stöder maskininlärning och att den består av märkning eller identifiering av komponenter. Men när det gäller djupinlärning och maskininlärning i sig: den grundläggande förutsättningen för maskininlärning är att datorsystem och program kan förbättra sina resultat på sätt som liknar mänskliga kognitiva processer, utan direkt mänsklig hjälp eller intervention, för att ge oss insikter. Med andra ord blir de självlärande maskiner som, precis som en människa, blir bättre på sitt jobb med mer övning. Denna "övning" uppnås genom att analysera och tolka mer (och bättre) träningsdata.
Vi har pratat om hur dataannotering eller datamärkning stöder maskininlärning och att den består av märkning eller identifiering av komponenter. Men när det gäller djupinlärning och maskininlärning i sig: den grundläggande förutsättningen för maskininlärning är att datorsystem och program kan förbättra sina resultat på sätt som liknar mänskliga kognitiva processer, utan direkt mänsklig hjälp eller intervention, för att ge oss insikter. Med andra ord blir de självlärande maskiner som, precis som en människa, blir bättre på sitt jobb med mer övning. Denna "övning" uppnås genom att analysera och tolka mer (och bättre) träningsdata.
Vad är datanotering?
Dataanteckning är processen att tillskriva, tagga eller märka data för att hjälpa maskininlärningsalgoritmer att förstå och klassificera informationen de bearbetar. Denna process är väsentlig för att träna AI-modeller, vilket gör att de kan förstå olika datatyper, såsom bilder, ljudfiler, videofilmer eller text.
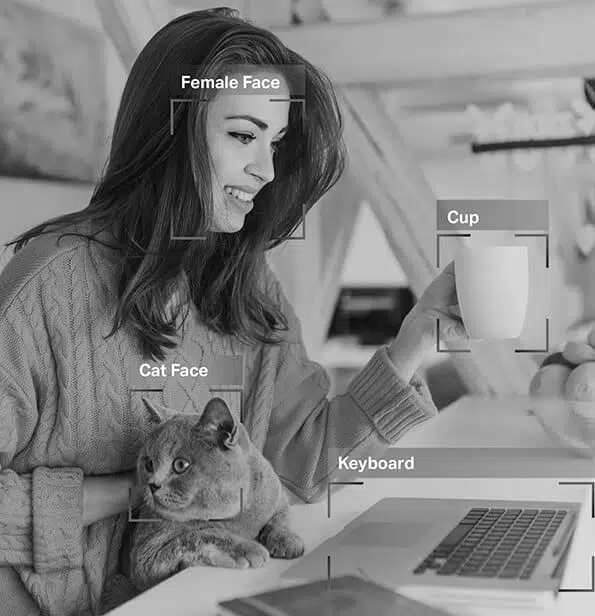
Föreställ dig en självkörande bil som förlitar sig på data från datorseende, naturlig språkbehandling (NLP) och sensorer för att fatta korrekta körbeslut. För att hjälpa bilens AI-modell att skilja mellan hinder som andra fordon, fotgängare, djur eller vägspärrar måste data den tar emot märkas eller kommenteras.
Vid övervakat lärande är dataanteckning särskilt avgörande, eftersom ju mer märkt data som matas till modellen, desto snabbare lär den sig att fungera autonomt. Kommenterad data gör att AI-modeller kan distribueras i olika applikationer som chatbots, taligenkänning och automatisering, vilket resulterar i optimal prestanda och tillförlitliga resultat.
Vad är ett verktyg för datamärkning/annotering?
 Enkelt uttryckt är det en plattform eller en portal som låter specialister och experter kommentera, märka eller märka datauppsättningar av alla typer. Det är en bro eller ett medium mellan rådata och resultaten som dina maskininlärningsmoduler i slutändan skulle slita ut.
Enkelt uttryckt är det en plattform eller en portal som låter specialister och experter kommentera, märka eller märka datauppsättningar av alla typer. Det är en bro eller ett medium mellan rådata och resultaten som dina maskininlärningsmoduler i slutändan skulle slita ut.
Ett datamärkningsverktyg är en on-prem eller molnbaserad lösning som kommenterar högkvalitativa utbildningsdata för maskininlärningsmodeller. Medan många företag förlitar sig på en extern leverantör för att göra komplexa kommentarer, har vissa organisationer fortfarande sina egna verktyg som antingen är specialbyggda eller baserade på freeware eller opensource-verktyg som finns på marknaden. Sådana verktyg är vanligtvis utformade för att hantera specifika datatyper, dvs bild, video, text, ljud, etc. Verktygen erbjuder funktioner eller alternativ som begränsningsrutor eller polygoner för datakommentatorer för att märka bilder. De kan bara välja alternativet och utföra sina specifika uppgifter.
Bildanmärkning

Från de datauppsättningar de har tränats på kan de omedelbart och exakt skilja dina ögon från din näsa och ditt ögonbryn från dina ögonfransar. Det är därför filtren du applicerar passar perfekt oavsett ansiktsform, hur nära du är din kamera och mer.
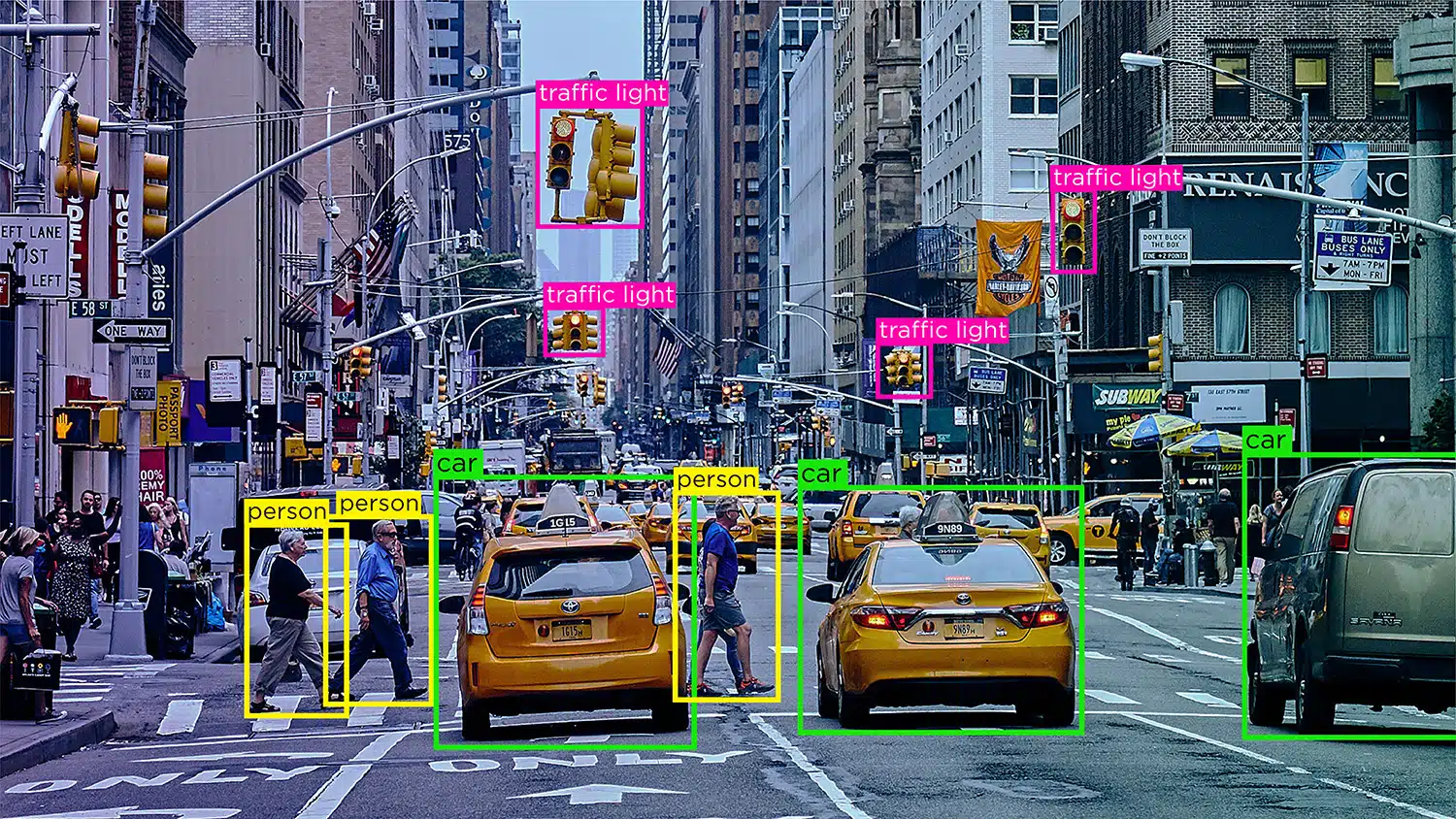
Så som ni vet nu, bildanmärkning är avgörande för moduler som innefattar ansiktsigenkänning, datorsyn, robotvision med mera. När AI -experter tränar sådana modeller lägger de till bildtexter, identifierare och sökord som attribut till deras bilder. Algoritmerna identifierar och förstår sedan från dessa parametrar och lär sig autonomt.
Bildklassificering – Bildklassificering innebär att tilldela fördefinierade kategorier eller etiketter till bilder baserat på deras innehåll. Den här typen av anteckningar används för att träna AI-modeller att känna igen och kategorisera bilder automatiskt.
Objektigenkänning/detektion – Objektigenkänning, eller objektdetektering, är processen att identifiera och märka specifika objekt i en bild. Den här typen av anteckningar används för att träna AI-modeller att lokalisera och känna igen objekt i verkliga bilder eller videor.
segmente~~POS=TRUNC – Bildsegmentering innebär att en bild delas upp i flera segment eller regioner, som var och en motsvarar ett specifikt objekt eller område av intresse. Den här typen av anteckningar används för att träna AI-modeller att analysera bilder på pixelnivå, vilket möjliggör mer exakt objektigenkänning och scenförståelse.
Ljudanteckning
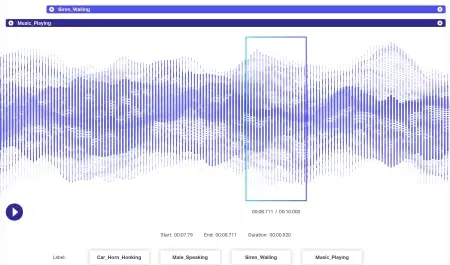
Ljuddata har ännu mer dynamik kopplat till sig än bilddata. Flera faktorer är förknippade med en ljudfil inklusive men definitivt inte begränsad till - språk, högtalardemografi, dialekter, humör, avsikt, känslor, beteende. För att algoritmer ska vara effektiva vid bearbetning bör alla dessa parametrar identifieras och märkas med tekniker som tidsstämpling, ljudmärkning och mer. Förutom endast verbala ledtrådar kan icke-verbala fall som tystnad, andetag, till och med bakgrundsbrus antecknas för att system ska förstå dem heltäckande.
Videonotering

Medan en bild fortfarande är, är en video en sammanställning av bilder som skapar en effekt av att objekt är i rörelse. Nu kallas varje bild i denna sammanställning en ram. När det gäller videoannotering innebär processen att man lägger till tangentpunkter, polygoner eller avgränsningsrutor för att kommentera olika objekt i fältet i varje ram.
När dessa ramar sys ihop kan rörelsen, beteendet, mönstren och mer läras av AI-modellerna i aktion. Det är bara igenom videoannotering att begrepp som lokalisering, rörelseoskärpa och objektspårning skulle kunna implementeras i system.
Textnotering

Idag är de flesta företag beroende av textbaserad data för unik insikt och information. Nu kan text vara allt från kundfeedback på en app till ett socialt media-omnämnande. Och till skillnad från bilder och videor som mest förmedlar avsikter som är raka framåt, kommer text med mycket semantik.
Som människor är vi inställda på att förstå sammanhanget för en fras, innebörden av varje ord, mening eller fras, relatera dem till en viss situation eller konversation och sedan inse den holistiska innebörden bakom ett uttalande. Maskiner däremot kan inte göra detta på exakta nivåer. Begrepp som sarkasm, humor och andra abstrakta element är okända för dem och därför blir textdatamärkning svårare. Det är därför som textannotering har några mer förfinade steg, såsom följande:
Semantisk kommentar - objekt, produkter och tjänster görs mer relevanta med lämpliga nyckelfrasmärkning och identifieringsparametrar. Chatbots är också gjorda för att efterlikna mänskliga konversationer på detta sätt.
Avsiktsnotering - användarens avsikt och det språk som används av dem är märkta för att maskiner ska förstå. Med detta kan modeller skilja på en begäran från ett kommando, eller rekommendation från en bokning och så vidare.
Sentimentkommentar – Sentimentkommentarer innebär att textdata märks med de känslor den förmedlar, till exempel positiv, negativ eller neutral. Denna typ av annotering används ofta i sentimentanalys, där AI-modeller tränas för att förstå och utvärdera de känslor som uttrycks i text.

Enhetsnotering - där ustrukturerade meningar är taggade för att göra dem mer meningsfulla och föra dem till ett format som kan förstås av maskiner. För att få detta att göra är två aspekter involverade - namngivna enhet erkännande och enhetslänkning. Namngiven entitetsigenkänning är när namn på platser, personer, händelser, organisationer och mer taggas och identifieras och entitetslänkning är när dessa taggar är länkade till meningar, fraser, fakta eller åsikter som följer dem. Sammantaget etablerar dessa två processer förhållandet mellan de associerade texterna och uttalandet kring det.
Textkategorisering – Meningar eller stycken kan taggas och klassificeras utifrån övergripande ämnen, trender, ämnen, åsikter, kategorier (sport, underhållning och liknande) och andra parametrar.
Viktiga steg i processen för datamärkning och datakommentarer
Dataanteckningsprocessen innefattar en serie väldefinierade steg för att säkerställa högkvalitativ och korrekt datamärkning för maskininlärningsapplikationer. Dessa steg täcker alla aspekter av processen, från datainsamling till export av kommenterade data för vidare användning.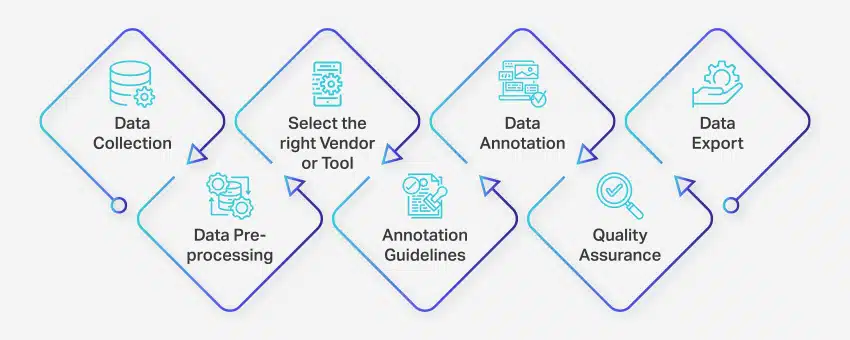
Så här går datakommentarer till:
- Datainsamling: Det första steget i dataanteckningsprocessen är att samla all relevant data, såsom bilder, videor, ljudinspelningar eller textdata, på en central plats.
- Dataförbehandling: Standardisera och förbättra den insamlade informationen genom att ta bort bilder, formatera text eller transkribera videoinnehåll. Förbearbetning säkerställer att data är redo för anteckning.
- Välj rätt leverantör eller verktyg: Välj ett lämpligt dataanteckningsverktyg eller leverantör baserat på ditt projekts krav. Alternativen inkluderar plattformar som Nanonets för datakommentarer, V7 för bildkommentarer, Appen för videokommentarer och Nanonets för dokumentkommentarer.
- Riktlinjer för anteckningar: Upprätta tydliga riktlinjer för anteckningsskrivare eller anteckningsverktyg för att säkerställa konsekvens och noggrannhet under hela processen.
- Anteckning: Märk och tagga data med hjälp av mänskliga annotatorer eller dataanteckningsprogram, enligt de fastställda riktlinjerna.
- Kvalitetssäkring (QA): Granska de annoterade data för att säkerställa noggrannhet och konsekvens. Använd flera blinda kommentarer, om nödvändigt, för att verifiera kvaliteten på resultaten.
- Dataexport: När du har slutfört datakommentaren exporterar du data i önskat format. Plattformar som Nanonets möjliggör sömlös dataexport till olika affärsprogram.
Hela dataanteckningsprocessen kan sträcka sig från några dagar till flera veckor, beroende på projektets storlek, komplexitet och tillgängliga resurser.
Funktioner för datanotering och datamärkningsverktyg
Dataanmälningsverktyg är avgörande faktorer som kan göra eller bryta ditt AI -projekt. När det gäller exakta utdata och resultat spelar kvaliteten på datauppsättningarna inte någon roll. Faktum är att dataanmälningsverktygen som du använder för att träna dina AI -moduler påverkar din output enormt mycket.
Därför är det viktigt att välja och använda det mest funktionella och lämpliga datamärkningsverktyget som uppfyller dina affärs- eller projektbehov. Men vad är ett dataannoteringsverktyg i första hand? Vilket syfte tjänar det? Finns det några typer? Tja, låt oss ta reda på det.
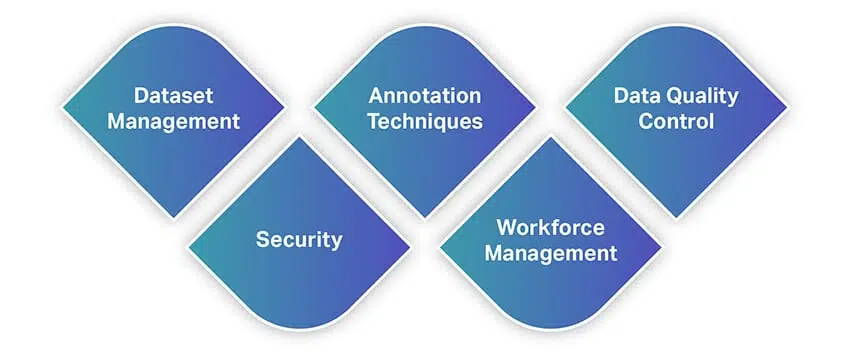
I likhet med andra verktyg erbjuder dataanmälningsverktyg ett brett utbud av funktioner och funktioner. För att ge dig en snabb uppfattning om funktioner, här är en lista över några av de mest grundläggande funktionerna du bör leta efter när du väljer ett dataannotationsverktyg.
Datasätthantering
Dataanmälningsverktyget du tänker använda måste stödja de datamängder du har i handen och låta dig importera dem till programvaran för märkning. Så att hantera dina datamängder är det primära funktionsverktygen. Samtida lösningar erbjuder funktioner som låter dig importera stora datamängder sömlöst, samtidigt som du kan organisera dina datamängder genom åtgärder som sortera, filtrera, klona, slå samman och mer.
När inmatningen av dina datamängder är klar exporterar vi dem som användbara filer. Verktyget du använder ska låta dig spara dina datamängder i det format du anger så att du kan mata in dem i dina ML -modeller.
Annoteringstekniker
Detta är vad ett dataanmälningsverktyg är byggt eller utformat för. Ett gediget verktyg bör erbjuda dig en rad annoteringstekniker för datamängder av alla typer. Detta är om du inte utvecklar en anpassad lösning för dina behov. Med ditt verktyg kan du kommentera video eller bilder från datorsyn, ljud eller text från NLP: er och transkriptioner med mera. Förfina detta ytterligare, det borde finnas alternativ för att använda avgränsande rutor, semantisk segmentering, kuboider, interpolering, sentimentanalys, taldelar, referenslösning och mer.
För den oinvigde finns det också AI-drivna datakommentareringsverktyg. Dessa kommer med AI -moduler som autonomt lär sig av en annotators arbetsmönster och automatiskt kommenterar bilder eller text. Sådan
moduler kan användas för att ge otrolig hjälp till annotatorer, optimera kommentarer och till och med genomföra kvalitetskontroller.
Datakvalitetskontroll
På tal om kvalitetskontroller rullar flera dataanmälningsverktyg ut där med inbäddade kvalitetskontrollmoduler. Dessa gör det möjligt för annotatorer att samarbeta bättre med sina teammedlemmar och hjälpa till att optimera arbetsflöden. Med den här funktionen kan annotatorer markera och spåra kommentarer eller feedback i realtid, spåra identiteter bakom personer som gör ändringar i filer, återställa tidigare versioner, välja etikettkonsensus och mer.
Säkerhet
Eftersom du arbetar med data bör säkerhet ha högsta prioritet. Du kan arbeta med konfidentiell information som t.ex. personuppgifter eller immateriella rättigheter. Så ditt verktyg måste ge lufttät säkerhet när det gäller var data lagras och hur de delas. Det måste tillhandahålla verktyg som begränsar åtkomst till gruppmedlemmar, förhindrar obehöriga nedladdningar och mer.
Bortsett från dessa måste säkerhetsstandarder och protokoll uppfyllas och följas.
Arbetsledning
Ett dataanmälningsverktyg är också en typ av projekthanteringsplattform, där uppgifter kan tilldelas gruppmedlemmar, samarbetsarbete kan ske, granskningar är möjliga och mer. Det är därför ditt verktyg ska passa in i ditt arbetsflöde och din process för optimerad produktivitet.
Dessutom måste verktyget också ha en minimal inlärningskurva, eftersom processen med dataanmärkning i sig är tidskrävande. Det tjänar inte något syfte att spendera för mycket tid på att bara lära sig verktyget. Så det borde vara intuitivt och sömlöst för alla att komma igång snabbt.
Vilka är fördelarna med datakommentarer?
Datakommentarer är avgörande för att optimera maskininlärningssystem och leverera förbättrade användarupplevelser. Här är några viktiga fördelar med datakommentarer:
- Förbättrad träningseffektivitet: Datamärkning hjälper maskininlärningsmodeller att bli bättre utbildade, vilket förbättrar den totala effektiviteten och ger mer exakta resultat.
- Ökad precision: Noggrant kommenterade data säkerställer att algoritmer kan anpassa och lära sig effektivt, vilket resulterar i högre precisionsnivåer i framtida uppgifter.
- Minskad mänsklig intervention: Avancerade verktyg för datakommentarer minskar avsevärt behovet av manuellt ingripande, effektiviserar processer och minskar relaterade kostnader.
Således bidrar datakommentarer till mer effektiva och exakta maskininlärningssystem samtidigt som de minimerar kostnaderna och manuella ansträngningar som traditionellt krävs för att träna AI-modeller.
Att bygga eller inte bygga ett dataannoteringsverktyg
En kritisk och övergripande fråga som kan komma att uppstå under ett datanotering eller datamärkningsprojekt är valet att antingen bygga eller köpa funktionalitet för dessa processer. Detta kan komma upp flera gånger i olika projektfaser, eller relaterat till olika delar av programmet. När man väljer om man ska bygga ett system internt eller förlita sig på leverantörer finns det alltid en avvägning.

Som du förmodligen kan berätta nu är datanotering en komplex process. Samtidigt är det också en subjektiv process. Det betyder att det inte finns något enda svar på frågan om du ska köpa eller bygga ett verktyg för datanotering. Många faktorer måste övervägas och du måste ställa dig själv några frågor för att förstå dina krav och inse om du verkligen behöver köpa eller bygga en.
För att göra det enkelt, här är några av de faktorer du bör tänka på.
Ditt mål
Det första elementet du behöver definiera är målet med din artificiella intelligens och maskininlärningskoncept.
- Varför implementerar du dem i ditt företag?
- Löser de ett verkligt problem som dina kunder står inför?
- Gör de någon front-end eller backend-process?
- Kommer du att använda AI för att introducera nya funktioner eller optimera din befintliga webbplats, app eller en modul?
- Vad gör din konkurrent i ditt segment?
- Har du tillräckligt med användningsfall som behöver AI-ingripande?
Svaren på dessa samlar dina tankar - som för närvarande kan vara överallt - till ett ställe och ger dig mer tydlighet.
AI -datainsamling / licensiering
AI -modeller kräver bara ett element för att fungera - data. Du måste identifiera varifrån du kan generera massiva mängder grundinformation. Om ditt företag genererar stora mängder data som behöver bearbetas för avgörande insikter om företag, verksamhet, konkurrentundersökningar, analys av marknadsvolatilitet, undersökning av kundbeteende och mer, behöver du ett verktyg för datakommentarer. Du bör dock också överväga mängden data du genererar. Som nämnts tidigare är en AI -modell bara lika effektiv som kvaliteten och kvantiteten på data som den matas. Så dina beslut bör alltid bero på denna faktor.
Om du inte har rätt data för att utbilda dina ML-modeller kan leverantörer komma till hands, vilket kan hjälpa dig med datalicensiering av rätt uppsättning data som krävs för att utbilda ML-modeller. I vissa fall kommer en del av värdet som säljaren ger att innebära både teknisk skicklighet och tillgång till resurser som kommer att främja projektsuccé.
budget
Ett annat grundläggande villkor som förmodligen påverkar varje enskild faktor som vi för närvarande diskuterar. Lösningen på frågan om du ska bygga eller köpa en dataanmärkning blir lätt när du förstår om du har tillräckligt med budget att spendera.
Komplexitet för efterlevnad
 Leverantörer kan vara oerhört hjälpsamma när det gäller datasekretess och korrekt hantering av känslig information. Ett av dessa typer av användningsfall handlar om ett sjukhus eller sjukvårdsrelaterat företag som vill använda kraften i maskininlärning utan att äventyra dess efterlevnad av HIPAA och andra dataskyddsregler. Även utanför det medicinska området skärper lagar som den europeiska dataskyddsförordningen kontrollen av datamängder och kräver mer vaksamhet från företagets intressenter.
Leverantörer kan vara oerhört hjälpsamma när det gäller datasekretess och korrekt hantering av känslig information. Ett av dessa typer av användningsfall handlar om ett sjukhus eller sjukvårdsrelaterat företag som vill använda kraften i maskininlärning utan att äventyra dess efterlevnad av HIPAA och andra dataskyddsregler. Även utanför det medicinska området skärper lagar som den europeiska dataskyddsförordningen kontrollen av datamängder och kräver mer vaksamhet från företagets intressenter.
Manpower
Dataanmärkning kräver skicklig arbetskraft att arbeta med oavsett storlek, skala och domän för ditt företag. Även om du genererar minsta data varje dag behöver du dataexperter för att arbeta med dina data för märkning. Så nu måste du inse om du har den nödvändiga arbetskraften på plats.Om du har det, är de skickliga på de verktyg och tekniker som krävs eller behöver de kompetens? Om de behöver utbildning, har du budgeten för att utbilda dem i första hand?
Dessutom tar de bästa dataanmärkningen och datamärkningsprogrammen ett antal ämnes- eller domenexperter och segmenterar dem enligt demografi som ålder, kön och expertområde - eller ofta i termer av de lokaliserade språken de kommer att arbeta med. Det är återigen där vi på Shaip talar om att få rätt personer i rätt säten och därigenom driva rätt mänskliga processer som leder dina programmatiska insatser till framgång.
Små och stora projektdrift och kostnadströsklar
I många fall kan leverantörsstöd vara mer ett alternativ för ett mindre projekt eller för mindre projektfaser. När kostnaderna är kontrollerbara kan företaget dra nytta av outsourcing för att effektivisera dataannotering eller datamärkningsprojekt.
Företag kan också titta på viktiga trösklar - där många leverantörer kopplar kostnader till mängden data som konsumeras eller andra resursriktmärken. Låt oss till exempel säga att ett företag har registrerat sig hos en leverantör för att göra den tråkiga datainmatningen som krävs för att konfigurera testuppsättningar.
Det kan finnas en dold tröskel i avtalet där till exempel affärspartnern måste ta ut ytterligare ett block med AWS-datalagring eller någon annan tjänstkomponent från Amazon Web Services eller någon annan tredjepartsleverantör. De överför det till kunden i form av högre kostnader, och det sätter prislappen utom kundens räckvidd.
I dessa fall hjälper mätning av de tjänster du får från leverantörer att hålla projektet överkomligt. Att ha rätt omfattning kommer att säkerställa att projektkostnaderna inte överstiger vad som är rimligt eller genomförbart för företaget i fråga.
Alternativ med öppen källkod och freeware
 Några alternativ till full leverantörsstöd innebär att man använder programvara med öppen källkod, eller till och med freeware, för att genomföra dataanmärkningar eller märkningsprojekt. Här finns det ett slags mellanväg där företag inte skapar allt från grunden, men också undviker att förlita sig för mycket på kommersiella leverantörer.
Några alternativ till full leverantörsstöd innebär att man använder programvara med öppen källkod, eller till och med freeware, för att genomföra dataanmärkningar eller märkningsprojekt. Här finns det ett slags mellanväg där företag inte skapar allt från grunden, men också undviker att förlita sig för mycket på kommersiella leverantörer.
Gör-det-själv-mentaliteten hos öppen källkod är i sig en slags kompromiss - ingenjörer och interna människor kan dra nytta av öppen källkod, där decentraliserade användarbaser erbjuder sitt eget slags gräsrotsstöd. Det kommer inte att vara som vad du får från en leverantör - du får inte 24/7 enkel hjälp eller svar på frågor utan att göra intern forskning - men prislappen är lägre.
Så, den stora frågan - När ska du köpa ett dataanmärkningsverktyg:
Som med många typer av högteknologiska projekt kräver denna typ av analys - när man ska bygga och när man ska köpa - dedikerad tanke och övervägande av hur dessa projekt kommer från och hanteras. De utmaningar som de flesta företag står inför i samband med AI / ML-projekt när de överväger alternativet "bygga" handlar inte bara om projektets byggnads- och utvecklingsdelar. Det finns ofta en enorm inlärningskurva för att ens komma till den punkt där sann AI / ML-utveckling kan uppstå. Med nya AI / ML-team och initiativ överstiger antalet "okända okända" långt antalet "kända okända."
| Bygga | Köp |
|---|---|
Alla tillgångar på ett och samma ställe
| Alla tillgångar på ett och samma ställe
|
Nackdelar:
| Nackdelar:
|
För att göra saker ännu enklare, överväga följande aspekter:
- när du arbetar med stora datamängder
- när du arbetar med olika sorter av data
- när funktionerna i dina modeller eller lösningar kan förändras eller utvecklas i framtiden
- när du har ett vagt eller generiskt användningsfall
- när du behöver en tydlig uppfattning om kostnaderna för att distribuera ett dataanmärkningsverktyg
- och när du inte har rätt arbetskraft eller skickliga experter för att arbeta med verktygen och letar efter en minimal inlärningskurva
Om dina svar var motsatta till dessa scenarier, bör du fokusera på att bygga ditt verktyg.
Hur man väljer rätt dataanteckningsverktyg för ditt projekt
Om du läser detta låter dessa idéer spännande och är definitivt lättare sagt än gjort. Så hur går det att utnyttja överflödet av redan existerande verktyg för datanotering där ute? Så nästa steg är att överväga de faktorer som är förknippade med att välja rätt dataanmärkningsverktyg.
Till skillnad från för några år tillbaka har marknaden utvecklats med massor av dataanmärkningsverktyg i praktiken idag. Företagen har fler möjligheter att välja en utifrån deras distinkta behov. Men varje enskilt verktyg har sina egna fördelar och nackdelar. För att fatta ett klokt beslut måste en objektiv väg också tas bort från subjektiva krav.
Låt oss titta på några av de avgörande faktorerna du bör tänka på i processen.
Definiera ditt användningsfall
För att välja rätt dataanmärkningsverktyg måste du definiera ditt användningsfall. Du bör inse om ditt krav handlar om text, bild, video, ljud eller en blandning av alla datatyper. Det finns fristående verktyg du kan köpa och det finns holistiska verktyg som låter dig utföra olika åtgärder på datamängder.
Verktygen idag är intuitiva och erbjuder dig alternativ när det gäller lagringsutrymmen (nätverk, lokalt eller moln), annoteringstekniker (ljud, bild, 3D och mer) och en mängd andra aspekter. Du kan välja ett verktyg baserat på dina specifika krav.
Fastställande av kvalitetskontrollstandarder
 Detta är en avgörande faktor att tänka på eftersom syftet och effektiviteten med dina AI-modeller är beroende av de kvalitetsstandarder du fastställer. Som en granskning måste du utföra kvalitetskontroller av de data du matar och de resultat som erhållits för att förstå om dina modeller utbildas på rätt sätt och för rätt ändamål. Frågan är dock hur tänker du upprätta kvalitetsstandarder?
Detta är en avgörande faktor att tänka på eftersom syftet och effektiviteten med dina AI-modeller är beroende av de kvalitetsstandarder du fastställer. Som en granskning måste du utföra kvalitetskontroller av de data du matar och de resultat som erhållits för att förstå om dina modeller utbildas på rätt sätt och för rätt ändamål. Frågan är dock hur tänker du upprätta kvalitetsstandarder?
Som med många olika typer av jobb kan många göra en dataanmärkning och märkning men de gör det med olika framgång. När du ber om en tjänst verifierar du inte automatiskt kvalitetskontrollnivån. Det är därför resultaten varierar.
Så vill du distribuera en konsensusmodell där kommentatorer ger feedback om kvalitet och korrigerande åtgärder vidtas direkt? Eller föredrar du provgranskning, guldstandarder eller korsning framför fackliga modeller?
Den bästa köpplanen kommer att säkerställa att kvalitetskontrollen är på plats från början genom att sätta standarder innan något slutligt avtal avtalas. När du fastställer detta bör du inte förbise felmarginaler också. Manuellt ingripande kan inte helt undvikas eftersom system kommer att ge fel med upp till 3%. Detta tar arbete i förväg, men det är värt det.
Vem kommer att kommentera dina uppgifter?
Nästa viktiga faktor är beroende av vem som antecknar dina data. Tänker du ha ett internt team eller vill du hellre få det outsourcat? Om du lägger ut outsourcing finns det legaliteter och efterlevnadsåtgärder som du måste tänka på på grund av de integritets- och sekretessproblem som är förknippade med data. Och om du har ett internt team, hur effektiva lär de sig ett nytt verktyg? Vad är din time-to-market med din produkt eller tjänst? Har du rätt kvalitetsmått och team för att godkänna resultaten?
The Vendor Vs. Partnerdebatt
 Dataanmärkningar är en samarbetsprocess. Det involverar beroenden och intrikat som interoperabilitet. Det betyder att vissa team alltid arbetar tillsammans med varandra och att ett av lagen kan vara din leverantör. Det är därför leverantören eller partnern du väljer är lika viktigt som verktyget du använder för datamärkning.
Dataanmärkningar är en samarbetsprocess. Det involverar beroenden och intrikat som interoperabilitet. Det betyder att vissa team alltid arbetar tillsammans med varandra och att ett av lagen kan vara din leverantör. Det är därför leverantören eller partnern du väljer är lika viktigt som verktyget du använder för datamärkning.
Med denna faktor bör aspekter som förmågan att hålla dina data och avsikter konfidentiella, avsikt att acceptera och arbeta med feedback, vara proaktiv när det gäller datarekvisitioner, flexibilitet i operationer och mer innan du skakar hand med en leverantör eller en partner . Vi har inkluderat flexibilitet eftersom kraven på dataanmärkningar inte alltid är linjära eller statiska. De kan förändras i framtiden när du skala ditt företag ytterligare. Om du för närvarande bara har att göra med textbaserad data kanske du vill kommentera ljud- eller videodata när du skala och ditt stöd bör vara redo att utvidga deras horisonter med dig.
Leverantörsengagemang
Ett av sätten att bedöma leverantörens engagemang är det stöd du får.
Varje köpplan måste ta hänsyn till denna komponent. Hur kommer stöd att se ut på marken? Vem kommer intressenterna och pekande människor att vara på båda sidor av ekvationen?
Det finns också konkreta uppgifter som måste stavas vad säljarens engagemang är (eller kommer att vara). Speciellt för ett datanotering eller datamärkningsprojekt kommer leverantören att tillhandahålla rådata aktivt eller inte? Vem kommer att agera som ämnesexperter, och vem kommer att anställa dem antingen som anställda eller oberoende entreprenörer?
Fallstudier
Här är några specifika fallstudieexempel som tar upp hur dataanmärkning och datamärkning verkligen fungerar på plats. På Shaip ser vi till att erbjuda högsta kvalitet och överlägsna resultat inom datakommentarer och datamärkning.
Mycket av ovanstående diskussion om standardprestationer för datanotering och datamärkning avslöjar hur vi närmar oss varje projekt och vad vi erbjuder till de företag och intressenter vi arbetar med.
Fallstudiematerial som visar hur detta fungerar:

I ett kliniskt datalicensprojekt bearbetade Shaip-teamet över 6,000 timmar ljud, tog bort all skyddad hälsoinformation (PHI) och lämnade HIPAA-kompatibelt innehåll för taligenkänningsmodeller för vården att arbeta med.
I den här typen av fall är det kriterierna och klassificeringen av prestationer som är viktiga. Rådata är i form av ljud, och det finns behov av att avidentifiera parter. När man till exempel använder NER-analys är det dubbla målet att avidentifiera och kommentera innehållet.
En annan fallstudie involverar en fördjupning konversationsdata för AI-träning projekt som vi genomförde med 3,000 14 lingvister som arbetade under en 27-veckorsperiod. Detta ledde till produktion av träningsdata på XNUMX språk, för att utveckla flerspråkiga digitala assistenter som kan hantera mänsklig interaktion på ett brett urval av modersmål.
I denna specifika fallstudie var behovet av att få rätt person i rätt stol uppenbart. Det stora antalet ämnesexperter och innehållsinmatningsoperatörer innebar att det fanns ett behov av organisation och procedureffektivisering för att få projektet gjort på en viss tidslinje. Vårt team kunde slå branschstandarden med stor marginal genom att optimera datainsamlingen och efterföljande processer.
Andra typer av fallstudier involverar saker som bot-utbildning och textannotering för maskininlärning. Återigen, i textformat är det fortfarande viktigt att behandla identifierade parter enligt sekretesslagar och att sortera genom rådata för att få de riktade resultaten.
Med andra ord, i arbetet över flera datatyper och format har Shaip visat samma viktiga framgång genom att tillämpa samma metoder och principer för både rådata och datalicenseringsscenarier.