


Vad är Conversational AI
Conversational AI är en avancerad form av artificiell intelligens som gör det möjligt för maskiner att delta i interaktiva, mänskliga dialoger med användare. Denna teknik förstår och tolkar mänskligt språk för att simulera naturliga samtal. Det kan lära sig av interaktioner över tid för att svara kontextuellt.
Konversations-AI-system används ofta i applikationer som chatbots, röstassistenter och kundsupportplattformar över digitala kanaler och telekommunikationskanaler.
Konversations-AI-marknaden har upplevt en snabb tillväxt de senaste åren. Konversations-AI, som ursprungligen utvecklades för underhållningsändamål, har blivit en integrerad del av det digitala ekosystemet. Här är några nyckelstatistik för att illustrera dess inverkan:
- Den globala konversations-AI-marknaden värderades till 6.8 miljarder USD 2021 och förväntas växa till 18.4 miljarder USD 2026 med en CAGR på 22.6 %. År 2028 förväntas marknadsstorleken nå $ 29.8 miljarder.
- Trots sin förekomst, 63% av användare är omedvetna om att de använder AI i sina dagliga liv.
- A Gartner undersökning fann att många företag identifierade chatbots som sin primära AI-applikation, med nästan 70 % av tjänstemännen som förväntas interagera med konversationsplattformar dagligen 2022.
- Sedan pandemin har volymen av interaktioner som hanteras av samtalsagenter ökat med lika mycket som 250% inom flera branscher.
- Andelen marknadsförare som använder AI för digital marknadsföring över hela världen ökade dramatiskt, från 29 % 2018 till 84% i 2020.
- 2022, 91% av vuxna röstassistentanvändare använde konversations-AI-teknik på sina smartphones.
- Att bläddra och söka efter produkter var det topp shoppingaktiviteter genomfördes med hjälp av röstassistentteknik bland amerikanska användare i en undersökning från 2021.
- Bland tekniska proffs över hela världen, nästan 80% använda virtuella assistenter för kundtjänst.
- År 2024 tror 73 % av de nordamerikanska beslutsfattarna inom kundtjänst att onlinechatt, videochatt, chatbots eller sociala medier kommer att vara mest använda kundtjänstkanalerna.
- I en undersökning från 2021, 86% av amerikanska chefer kom överens om att AI skulle bli en "mainstream-teknik" inom deras företag.
- Från februari 2022, 53% av amerikanska vuxna hade kommunicerat med en AI-chatbot för kundtjänst under det senaste året.
- 2022, 3.5 miljarder chatbot-appar nåddes över hela världen.
- Smakämnen tre främsta anledningarna Amerikanska konsumenter använder en chatbot för kontorstid (18 %), produktinformation (17 %) och kundtjänstförfrågningar (16 %).
Denna statistik visar det ökande antagandet och inflytandet av konversations-AI inom olika branscher och konsumentbeteenden.
Hur fungerar Conversational AI
Conversational AI använder naturlig språkbehandling (NLP) och andra sofistikerade algoritmer för att delta i kontextrika dialoger. Eftersom AI möter ett bredare utbud av användarinmatningar, förbättrar den dess mönsterigenkänning och förutsägande förmåga. Processen för konversations-AI som interagerar med användare kan delas upp i fyra nyckelsteg:

Steg 1: Ingångsinsamling – Användare ger sin input antingen via text eller röst.
Steg 2: Indatabearbetning – När inmatningen är i textform används naturlig språkförståelse (NLU) för att extrahera mening ur orden. För röstinmatningar används automatisk taligenkänning (ASR) först för att konvertera ljud till språktokens som kan analyseras ytterligare.
Steg 3: Generering av svar – Naturliga språkgenereringstekniker används för att svara på användarens förfrågan på lämpligt sätt.
Steg 4: Kontinuerlig förbättring – Konversations-AI-system analyserar användarinmatningar över tid, förfinar deras svar för att säkerställa noggrannhet och relevans.


Minska vanliga datautmaningar i konversations-AI
Conversational AI förvandlar dynamiskt kommunikation mellan människa och dator. Och många företag är angelägna om att utveckla avancerade konversations-AI-verktyg och applikationer som kan förändra hur affärer görs. Innan du utvecklar en chatbot som kan underlätta bättre kommunikation mellan dig och dina kunder måste du dock titta på de många utvecklingsfällor du kan möta.
Språkmångfald
 Att utveckla en chattassistent som kan tillgodose flera språk är utmanande. Dessutom gör den stora mångfalden av globala språk det till en utmaning att utveckla en chatbot som sömlöst ger kundservice till alla kunder.
Att utveckla en chattassistent som kan tillgodose flera språk är utmanande. Dessutom gör den stora mångfalden av globala språk det till en utmaning att utveckla en chatbot som sömlöst ger kundservice till alla kunder.
2022, cirka 1.5 miljarder människor talade engelska över hela världen, följt av kinesisk mandarin med 1.1 miljarder talare. Även om engelska är det mest talade och studerade främmande språket globalt, bara ca 20% av världens befolkning talar det. Det gör att resten av världens befolkning – 80 % – talar andra språk än engelska. Så när du utvecklar en chatbot måste du också ta hänsyn till språklig mångfald.
Språkvariabilitet
Människor talar olika språk och samma språk olika. Tyvärr är det fortfarande omöjligt för en maskin att helt förstå talspråkets variation, med hänsyn till känslor, dialekter, uttal, accenter och nyanser.
Våra ord och språkval återspeglas också i hur vi skriver. En maskin kan förväntas förstå och uppskatta språkets variation endast när en grupp annotatorer tränar den på olika taldatauppsättningar.
Dynamik i tal
En annan stor utmaning för att utveckla en konversations-AI är att ta med taldynamiken i striden. Till exempel använder vi flera fillers, pauser, meningsfragment och otydliga ljud när vi pratar. Dessutom är tal mycket mer komplext än det skrivna ordet eftersom vi inte brukar pausa mellan varje ord och betona rätt stavelse.
När vi lyssnar på andra, tenderar vi att härleda avsikten och meningen med deras samtal med hjälp av vår livslängd av erfarenheter. Som ett resultat kontextualiserar och förstår vi deras ord även när det är tvetydigt. En maskin klarar dock inte av denna kvalitet.
Bullriga data
Bullriga data eller bakgrundsljud är data som inte ger värde till konversationerna, som dörrklockor, hundar, barn och andra bakgrundsljud. Därför är det viktigt att skrubba eller filtrera ljudfiler av dessa ljud och träna AI-systemet att identifiera de ljud som spelar roll och de som inte gör det.
För- och nackdelar med olika taldatatyper
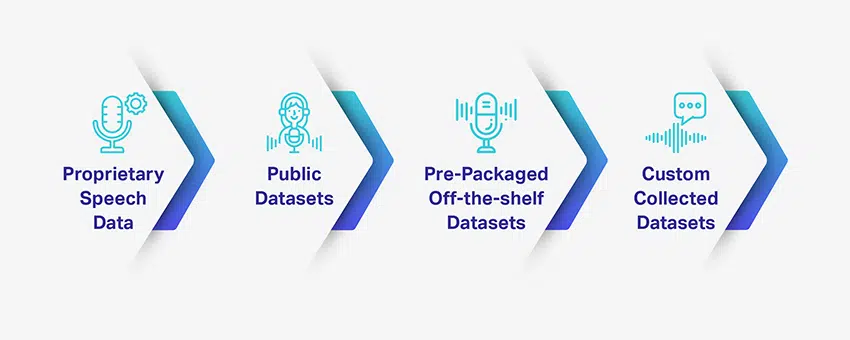
 Att bygga ett AI-drivet röstigenkänningssystem eller en konversations-AI kräver massor av tränings- och testdatauppsättningar. Det är dock inte lätt att ha tillgång till sådana kvalitetsdatauppsättningar – tillförlitliga och uppfylla dina specifika projektbehov. Ändå finns det tillgängliga alternativ för företag som letar efter utbildningsdatauppsättningar, och varje alternativ har fördelar och nackdelar.
Att bygga ett AI-drivet röstigenkänningssystem eller en konversations-AI kräver massor av tränings- och testdatauppsättningar. Det är dock inte lätt att ha tillgång till sådana kvalitetsdatauppsättningar – tillförlitliga och uppfylla dina specifika projektbehov. Ändå finns det tillgängliga alternativ för företag som letar efter utbildningsdatauppsättningar, och varje alternativ har fördelar och nackdelar.
Om du letar efter en generisk datauppsättningstyp, har du många alternativ för offentligt tal tillgängliga. Men för något mer specifikt och relevant för ditt projektkrav kan du behöva samla in och anpassa det på egen hand.
Proprietära taldata
Det första stället att leta är ditt företags egna data. Men eftersom du har den lagliga rätten och samtycket att använda dina kundtalsdata, skulle du kunna använda denna enorma datauppsättning för att träna och testa dina projekt.
Alla tillgångar på ett och samma ställe
- Inga ytterligare kostnader för insamling av utbildningsdata
- Utbildningsdata är sannolikt relevant för ditt företag
- Taldata har också naturlig bakgrundsakustik, dynamiska användare och enheter.
Nackdelar:
- Att använda sådan data kan kosta dig massor av pengar på tillstånd att spela in och använda.
- Taldata kan ha språkliga, demografiska eller kundbasbegränsningar
- Data kan vara gratis, men du betalar fortfarande för bearbetning, transkription, taggning och mer.
Offentliga datamängder
Offentliga taldatauppsättningar är ett annat alternativ om du inte tänker använda din. Dessa datauppsättningar är en del av det offentliga och skulle kunna samlas in för projekt med öppen källkod.
Fördelar:
- Offentliga datauppsättningar är gratis och idealiska för lågbudgetprojekt
- De är tillgängliga för omedelbar nedladdning
- Offentliga datauppsättningar finns i en mängd olika skriptade och oskriptade exempeluppsättningar.
Nackdelar:
- Kostnaderna för bearbetning och kvalitetssäkring kan bli höga
- Kvaliteten på datauppsättningar för offentligt tal varierar i betydande grad
- De talprover som erbjuds är vanligtvis generiska, vilket gör dem olämpliga för att utveckla specifika talprojekt
- Datauppsättningarna är vanligtvis partiska mot det engelska språket
Färdigförpackade/av hyllan datamängder
Utforska färdigförpackade datauppsättningar är ett annat alternativ om offentliga data eller proprietära insamling av taldata passar inte dina behov.
Säljaren har samlat in färdigpaketerade taldatauppsättningar för det specifika syftet att sälja vidare till kunder. Denna typ av datauppsättning kan användas för att utveckla generiska applikationer eller specifika ändamål.
Fördelar:
- Du kan få tillgång till en datauppsättning som passar ditt specifika behov av taldata
- Det är billigare att använda en färdigförpackad datauppsättning än att samla in din egen
- Du kanske kan få tillgång till datasetet snabbt
Nackdelar:
- Eftersom datamängden är förpackad är den inte anpassad till dina projektbehov.
- Dessutom är datasetet inte unikt för ditt företag eftersom alla andra företag kan köpa det.
Välj anpassade insamlade datauppsättningar
När du bygger en talapplikation skulle du behöva en utbildningsdatauppsättning som uppfyller alla dina specifika krav. Det är dock högst osannolikt att du får tillgång till en färdigförpackad datauppsättning som tillgodoser de unika kraven i ditt projekt. Det enda tillgängliga alternativet skulle vara att skapa din datauppsättning eller skaffa datauppsättningen genom tredjepartslösningsleverantörer.
Datauppsättningarna för dina tränings- och testbehov är helt anpassningsbara. Du kan inkludera språkdynamik, taldatavariation och tillgång till olika deltagare. Dessutom kan datasetet skalas för att möta dina projektkrav i tid.
Fördelar:
- Datauppsättningar samlas in för ditt specifika användningsfall. Risken för att AI-algoritmer avviker från de avsedda resultaten minimeras.
- Kontrollera och minska bias i AI-data
Nackdelar:
- Datauppsättningarna kan vara kostsamma och tidskrävande; men fördelarna uppväger alltid kostnaderna.

Branscher som använder Conversational AI
För närvarande används konversations-AI övervägande som chatbots. Men flera industrier implementerar denna teknik för att få enorma fördelar. Några av de branscher som använder konversations-AI är:
Sjukvård
 Conversational AI har en enorm inverkan på sjukvårdssektorn. Conversational AI har visat sig vara fördelaktigt för patienter, läkare, personal, sjuksköterskor och annan medicinsk personal.
Conversational AI har en enorm inverkan på sjukvårdssektorn. Conversational AI har visat sig vara fördelaktigt för patienter, läkare, personal, sjuksköterskor och annan medicinsk personal.
Några av fördelarna är
- Patientengagemang i efterbehandlingsfasen
- Mötesschemaläggning chatbots
- Svara på vanliga frågor och allmänna frågor
- Bedömning av symptom
- Identifiera intensivvårdspatienter
- Upptrappning av akuta fall
E-handel
 Conversational AI hjälper e-handelsföretag att engagera sig med sina kunder, ge skräddarsydda rekommendationer och sälja produkter.
Conversational AI hjälper e-handelsföretag att engagera sig med sina kunder, ge skräddarsydda rekommendationer och sälja produkter.
E-handelsbranschen drar nytta av fördelarna med denna klassens bästa teknik.
- Samla in kundinformation
- Ge relevant produktinformation och rekommendationer
- Förbättra kundnöjdheten
- Hjälper till med beställningar och returer
- Svar på vanliga frågor
- Korsförsäljning och merförsäljning av produkter
Banking
 Banksektorn använder konversationsverktyg för AI för att förbättra kundinteraktioner, bearbeta förfrågningar i realtid och ge en förenklad och enhetlig kundupplevelse över flera kanaler.
Banksektorn använder konversationsverktyg för AI för att förbättra kundinteraktioner, bearbeta förfrågningar i realtid och ge en förenklad och enhetlig kundupplevelse över flera kanaler.
- Låt kunderna kontrollera sina saldon i realtid
- Hjälp med insättningar
- Hjälpa till med att lämna in skatter och ansöka om lån
- Effektivisera bankprocessen genom att skicka räkningspåminnelser, aviseringar och varningar
Försäkring
 I likhet med banksektorn drivs försäkringsbranschen också digitalt av konversations-AI och skördar dess fördelar. Till exempel hjälper konversations-AI försäkringsbranschen att tillhandahålla snabbare och mer pålitliga sätt att lösa konflikter och anspråk.
I likhet med banksektorn drivs försäkringsbranschen också digitalt av konversations-AI och skördar dess fördelar. Till exempel hjälper konversations-AI försäkringsbranschen att tillhandahålla snabbare och mer pålitliga sätt att lösa konflikter och anspråk.
- Ge policyrekommendationer
- Snabbare skadereglering
- Eliminera väntetider
- Samla in feedback och recensioner från kunder
- Skapa kundmedvetenhet om policyer
- Hantera snabbare anspråk och förnyelse

Shaip erbjudande
När det gäller att tillhandahålla kvalitativa och tillförlitliga datauppsättningar för utveckling av avancerade talapplikationer för interaktion mellan människa och maskin, har Shaip varit ledande på marknaden med sina framgångsrika implementeringar. Men med en akut brist på chatbots och talassistenter söker företag i allt högre grad Shaip – marknadsledaren – för att tillhandahålla anpassade, exakta och kvalitetsdatauppsättningar för utbildning och testning för AI-projekt.
Genom att kombinera naturlig språkbehandling kan vi tillhandahålla personliga upplevelser genom att hjälpa till att utveckla korrekta talapplikationer som effektivt efterliknar mänskliga konversationer. Vi använder en mängd avancerade teknologier för att leverera högkvalitativa kundupplevelser. NLP lär maskiner att tolka mänskliga språk och interagera med människor.
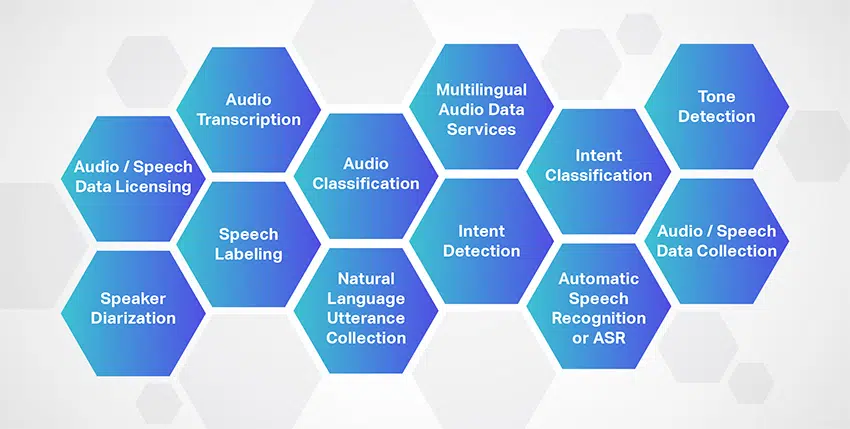
Ljudtranskription
Shaip är en ledande leverantör av ljudtransskriptionstjänster som erbjuder en mängd olika tal-/ljudfiler för alla typer av projekt. Dessutom erbjuder Shaip en 100 % mänskligt genererad transkriptionstjänst för att konvertera ljud- och videofiler – intervjuer, seminarier, föreläsningar, podcasts etc. till lättläslig text.
Talmärkning
Shaip erbjuder omfattande talmärkningstjänster genom att sakkunnigt separera ljud och tal i en ljudfil och märka varje fil. Genom att exakt separera liknande ljudljud och kommentera dem,
Speaker Diarization
Sharps expertis sträcker sig till att erbjuda utmärkta högtalardiariseringslösningar genom att segmentera ljudinspelningen baserat på deras källa. Dessutom identifieras och klassificeras högtalargränserna exakt, såsom högtalare 1, högtalare 2, musik, bakgrundsljud, fordonsljud, tystnad med mera, för att bestämma antalet högtalare.
Ljudklassificering
Anteckningar börjar med att klassificera ljudfiler i förutbestämda kategorier. Kategorierna beror främst på projektets krav, och de inkluderar vanligtvis användarens avsikt, språk, semantisk segmentering, bakgrundsljud, det totala antalet talare med mera.
Samling av naturliga språkyttringar/ uppvaknande ord
Det är svårt att förutse att klienten alltid kommer att välja liknande ord när han ställer en fråga eller initierar en förfrågan. T.ex. "Var är närmaste restaurang?" "Hitta restauranger nära mig" eller "Finns det en restaurang i närheten?"
Alla tre yttranden har samma avsikt men är olika formulerade. Genom permutation och kombination kommer experterna på Shaip att identifiera alla möjliga kombinationer för att formulera samma begäran. Shaip samlar in och kommenterar yttranden och väckande ord, med fokus på semantik, sammanhang, tonfall, diktion, timing, stress och dialekter.
Flerspråkiga ljuddatatjänster
Flerspråkiga ljuddatatjänster är ett annat mycket föredraget erbjudande från Shaip, eftersom vi har ett team av datainsamlare som samlar in ljuddata på över 150 språk och dialekter över hela världen.
Avsiktsdetektering
Mänsklig interaktion och kommunikation är ofta mer komplicerad än vi ger dem kredit för. Och denna medfödda komplikation gör det svårt att träna en ML-modell för att förstå mänskligt tal korrekt.
Dessutom kan olika personer från samma demografiska eller olika demografiska grupper uttrycka samma avsikt eller känslor på olika sätt. Så, taligenkänningssystemet måste tränas för att känna igen gemensamma avsikter oavsett demografi.
För att säkerställa att du kan träna och utveckla en förstklassig ML-modell tillhandahåller våra logopeder omfattande och mångsidiga datauppsättningar för att hjälpa systemet att identifiera de olika sätt som människor uttrycker samma avsikter på.
Syfte Klassificering
På samma sätt som att identifiera samma avsikt från olika personer, bör dina chatbots också tränas för att kategorisera kundkommentarer i olika kategorier – förutbestämda av dig. Varje chatbot eller virtuell assistent är designad och utvecklad med ett specifikt syfte. Shaip kan klassificera användarens avsikt i fördefinierade kategorier efter behov.
Automatisk taligenkänning eller ASR
Taligenkänning” syftar på att konvertera talade ord till text; dock syftar röstigenkänning & talaridentifiering till att identifiera både talat innehåll och talarens identitet. ASR:s noggrannhet bestäms av olika parametrar, dvs högtalarvolym, bakgrundsljud, inspelningsutrustning etc.
Tondetektering
En annan intressant aspekt av mänsklig interaktion är ton – vi känner igen innebörden av ord beroende på vilken ton de uttalas med. Även om det vi säger är viktigt, förmedlar hur vi säger de orden också mening.
Till exempel en enkel fras som "Vilken glädje!" kan vara ett utrop av lycka och kan också vara tänkt att vara sarkastisk. Det beror på tonen och stressen.
'Vad gör du?'
'Vad gör du?'
Båda dessa meningar har de exakta orden, men betoningen på orden är annorlunda, vilket förändrar hela meningen med meningarna. Chatboten är tränad att identifiera lycka, sarkasm, ilska, irritation och fler uttryck. Det är där expertisen hos Sharps logopeder och annotatorer kommer in i bilden.
Licensiering av ljud/taldata
Shaip erbjuder oöverträffade standarduppsättningar av talkvalitet som kan anpassas för att passa ditt projekts specifika behov. De flesta av våra datauppsättningar kan passa in i varje budget, och data är skalbar för att möta alla framtida projektkrav. Vi erbjuder över 40 100 timmar av färdiga taluppsättningar på över 50 dialekter på över XNUMX språk. Vi tillhandahåller också en rad olika ljudtyper, inklusive spontana, monologer, manus och väckande ord. Se hela Datakatalog.
Insamling av ljud/tal
När det råder brist på högkvalitativa taluppsättningar kan den resulterande tallösningen vara full av problem och bristande tillförlitlighet. Shaip är en av få leverantörer som levererar flerspråkiga ljudsamlingar, ljudtranskription och anteckningsverktyg och tjänster som är helt anpassningsbara för projektet.
Taldata kan ses som ett spektrum, från naturligt tal i ena änden till onaturligt tal i den andra. I naturligt tal har du talaren som pratar på ett spontant konversationssätt. Å andra sidan låter onaturligt tal begränsat när talaren läser av ett manus. Slutligen uppmanas talare att uttala ord eller fraser på ett kontrollerat sätt mitt i spektrumet.
Sharps expertis sträcker sig till att tillhandahålla olika typer av taldatauppsättningar på över 150 språk

































Framgångsberättelser
Vi har arbetat med några av de främsta företagen och varumärkena och har försett dem med konversations-AI-lösningar av högsta klass.
Några av våra framgångshistorier inkluderar,
- Vi hade utvecklat en taligenkänningsdatauppsättning med mer än 10,000 XNUMX timmars flerspråkiga transkriptioner, konversationer och ljudfiler för att träna och bygga en live chatbot.
- Vi byggde en högkvalitativ datauppsättning av 1000-tals konversationer med 6 varv per konversation som används för försäkringschatbotträning.
- Vårt team på över 3000 1000 språkexperter tillhandahöll mer än 27 XNUMX timmar med ljudfiler och utskrifter på XNUMX modersmål för att träna och testa en digital assistent.
- Vårt team av kommentatorer och språkexperter samlade också in och levererade 20,000 27 och fler timmar av yttranden på mer än XNUMX globala språk snabbt.
- Våra tjänster för automatisk taligenkänning är en av de mest föredragna av branschen. Vi tillhandahöll tillförlitligt märkta ljudfiler, vilket säkerställde specifik uppmärksamhet på uttal, ton och avsikt genom att använda ett brett utbud av transkriptioner och lexikon från olika högtalarset för att förbättra tillförlitligheten hos ASR-modeller.
Våra framgångshistorier härrör från vårt teams engagemang att alltid tillhandahålla de bästa tjänsterna med den senaste tekniken till våra kunder. Det som gör oss annorlunda är att vårt arbete stöds av expertkommentarer som tillhandahåller opartiska och korrekta datauppsättningar med anteckningar i guldstandard.
Vårt datainsamlingsteam med över 30,000 XNUMX bidragsgivare kan hämta, skala och leverera högkvalitativa datauppsättningar som hjälper till med snabb implementering av ML-modeller. Dessutom arbetar vi på den senaste AI-baserade plattformen och har förmågan att tillhandahålla accelererade taldatalösningar till företag mycket snabbare än våra närmaste konkurrenter.
