









- Användningsfall: Objektigenkänningsmodell
- Format: Video
- Volym: 5,000+
- Anteckning: Nej

- Användningsfall: Dok. Igenkänningsmodell
- Format: Bilder
- Volym: 15,900+
- Anteckning: Nej
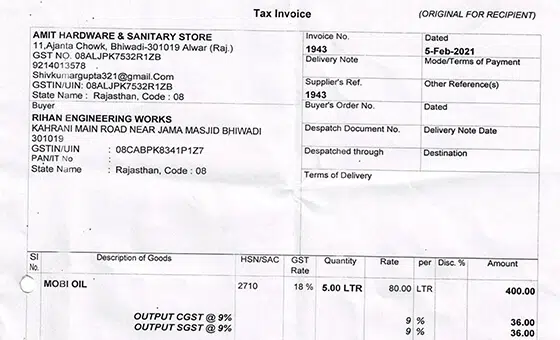
- Användningsfall: Invoice Recog. Modell
- Format: Bilder
- Volym: 45,000+
- Anteckning: Nej

- Användningsfall: Nr. Plattigenkänning
- Format: Bilder
- Volym: 3,500+
- Anteckning: Nej

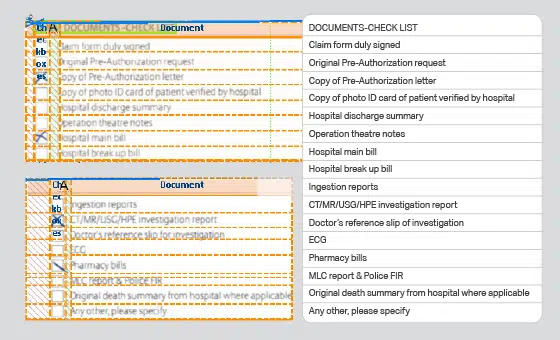
- Användningsfall: OCR-modell
- Format: Bilder
- Volym: 90,000+
- Anteckning: Ja

- Användningsfall: Flerspråkig OCR-modell
- Format: Bilder
- Volym: 23,500+
- Anteckning: Ja
- Användningsfall: Objektdetektionsmodell
- Format: Bilder
- Volym: 11,500+
- Anteckning: Nej

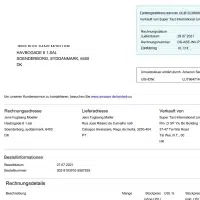
- Användningsfall: Kvitto AI-modeller
- Format: Bilder
- Volym: 75,000+
- Anteckning: Nej

Personer
Dedikerade och utbildade team:
- 30,000+ medarbetare för datainsamling, märkning och kvalitetssäkring
- Godkänd projektledningsteam
- Erfaren produktutvecklingsteam
- Talent Pool Sourcing & Onboarding Team

Behandla
Högsta processeffektivitet säkerställs med:
- Robust 6 Sigma Stage-Gate-process
- Ett dedikerat team med 6 Sigma-svarta bälten - Viktiga processägare och kvalitetskrav
- Kontinuerlig förbättring och återkopplingsslinga

plattform
Den patenterade plattformen erbjuder fördelar:
- Webbaserad end-to-end-plattform
- Oklanderlig kvalitet
- Snabbare TAT
- Sömlös leverans



Att skapa klinisk NLP är en kritisk uppgift som kräver enorm domenexpertis för att lösa. Jag kan tydligt se att du ligger flera år före Google på detta område. Jag vill arbeta med dig och skala dig.
Google, Inc. Direktör
Mitt ingenjörsteam arbetade med Shaips team i mer än 2 år under utvecklingen av API för hälsotal. Vi har blivit imponerade av deras arbete inom sjukvårdsspecifik NLP och vad de kan uppnå med komplexa datamängder.
Google, Inc. Teknisk chef