Fördelar med OCR
Optisk teckenigenkänning – OCR-teknik – ger en rad fördelar, varav några är:
Öka processens hastighet:
Genom att snabbt omvandla ostrukturerad data till maskinläsbar och sökbar information hjälper tekniken till att öka hastigheten på affärsprocesser.
Ökar noggrannheten:
Risken för mänskliga fel elimineras, vilket förbättrar den övergripande noggrannheten i teckenigenkänningen.
Minskar bearbetningskostnaderna:
Programvaran för optisk teckenigenkänning är inte helt beroende av andra teknologier, vilket minskar bearbetningskostnaderna.
Förbättrar produktiviteten:
Eftersom information är lättillgänglig och sökbar har medarbetarna mer tid på sig att utföra produktiva uppgifter och uppnå mål.
Förbättrar kundnöjdheten:
Tillgången på information i ett lättsökbart format säkerställer högre nöjdhetsnivåer och en bättre kundupplevelse.
Användningsfall och applikationer
Bevarande av dokument / Digitalisering av dokument
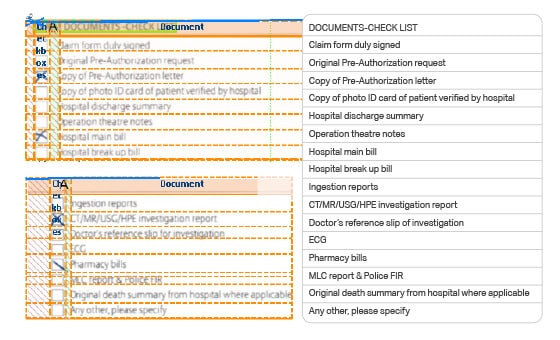 Gamla historiska dokument av värde kan bevaras, lagras och göras oförstörbara genom att konvertera dem till digitaliserat format. OCR-teknik används för att digitalisera antika och sällsynta böcker, så dessa manuskript med oregelbundna typsnitt kan ändras digitalt och göras sökbara för framtiden.
Gamla historiska dokument av värde kan bevaras, lagras och göras oförstörbara genom att konvertera dem till digitaliserat format. OCR-teknik används för att digitalisera antika och sällsynta böcker, så dessa manuskript med oregelbundna typsnitt kan ändras digitalt och göras sökbara för framtiden.
Bank och ekonomi
Bank- och finanssektorn använder ULT-tekniken till sitt yttersta. Denna teknik hjälper till att förbättra förebyggande av säkerhetsbedrägerier, minska risker och snabbare bearbetning. Banker och bankappar använder OCR för att extrahera viktiga data från checkar som kontonummer, belopp och handsignatur. OCR hjälper till med snabbare handläggning av låne- och bolåneansökningar, fakturor och lönebesked.
Innan OCR blev vanligare var alla bankdokument som register, kvitton, utdrag och checkar fysiska. Med OCR-digitalisering kan banker och finansinstitut effektivisera processer, eliminera manuella fel och förbättra processeffektiviteten genom att snabbt komma åt data.
Nummerplåtsigenkänning
 OCR-tekniken används i stor utsträckning för att identifiera siffror och text på nummerskyltar. Denna teknik används för att identifiera förlorade bilar, beräkningar av parkeringsavgifter och förebygga fordonsbrott.
OCR-tekniken används i stor utsträckning för att identifiera siffror och text på nummerskyltar. Denna teknik används för att identifiera förlorade bilar, beräkningar av parkeringsavgifter och förebygga fordonsbrott.
OCR-teknik hjälper till att implementera trafiksäkerhetsregler för att undvika bedrägerier och brott. Eftersom registreringsskyltarna på ett fordon är kopplade till förarens legitimation är identifieringen lättare.
Dessutom består registreringsskyltarna av ett välskrivet gäng siffror och text som inte är svår att läsa för AI-modellen, vilket gör det enklare och mer exakt.
Text-till-tal
Text-till-tal tillämpning av OCR-teknik är en utmärkt hjälp för visuellt utmanade personer att fungera med större lätthet. OCR-teknik hjälper till att skanna fysiska och digitala texter och använda röstenheter. Innehållet läses sedan upp. Även om text-till-tal-aspekten av OCR-teknik har varit en av de första applikationerna, är den nu utvecklad och avancerad för att tillgodose de unika behoven hos visuellt utmanade människor genom att stödja flera dialekter och språk.
Transkription av Multi-category Skannade pappersdokument dataset
 Med OCR-teknik transkriberas också fakturor, kvitton, räkningar och andra dokument av olika kategorier effektivt. Nyhetsbrev, tidningar med siffror i cirklar, kryssruteformulär och dokument med flera kategorier som skatteformulär och manualer kan också digitaliseras.
Med OCR-teknik transkriberas också fakturor, kvitton, räkningar och andra dokument av olika kategorier effektivt. Nyhetsbrev, tidningar med siffror i cirklar, kryssruteformulär och dokument med flera kategorier som skatteformulär och manualer kan också digitaliseras.
Transkribera medicinska etiketter med OCR
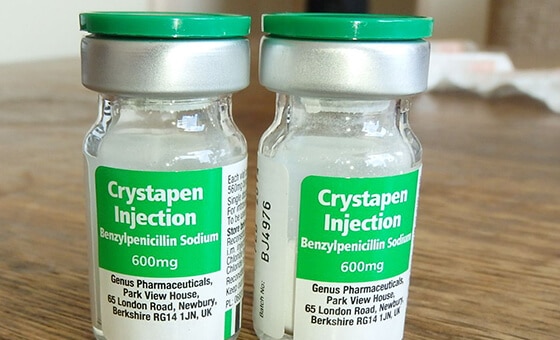 Genom att hjälpa till med att skanna receptbelagda medicinska etiketter med OCR är det nu möjligt att automatiskt fånga medicinska data. Det medicinska data fångas in från handskrivna recept, läkemedelsinformation och kvantitet för att undvika manuella fel, dubbelarbete och slarv.
Genom att hjälpa till med att skanna receptbelagda medicinska etiketter med OCR är det nu möjligt att automatiskt fånga medicinska data. Det medicinska data fångas in från handskrivna recept, läkemedelsinformation och kvantitet för att undvika manuella fel, dubbelarbete och slarv.
Med OCR kan sjukvårdsindustrin snabbt skanna, lagra och söka efter en patients medicinska historia. OCR gör det möjligt att digitalisera och lagra skanningsrapporter, behandlingshistorik, sjukhusjournaler, försäkringsjournaler, röntgenbilder och andra dokument. Genom att digitalisera, transkribera och lagra medicinska etiketter gör OCR det enkelt att effektivisera processflödet och påskynda vården.
Upptäcka gata/väg & extrahera information Street Board-data med OCR
 Automatisk detektering, identifiering och klassificering av väg-/gatuskyltar görs med OCR. Genom att upptäcka vägskyltar leder OCR förare mot en säkrare resa. OCR-tekniken fungerar lika bra under svaga ljusförhållanden, upptäcker vägskyltar på flera språk och olika formade skyltar och klassificerar desamma för framtiden.
Automatisk detektering, identifiering och klassificering av väg-/gatuskyltar görs med OCR. Genom att upptäcka vägskyltar leder OCR förare mot en säkrare resa. OCR-tekniken fungerar lika bra under svaga ljusförhållanden, upptäcker vägskyltar på flera språk och olika formade skyltar och klassificerar desamma för framtiden.
Att utveckla en intelligent teckenigenkänning verktyget måste du träna det med den projektspecifika datamängden.
På Shaip tillhandahåller vi en helt anpassad dokumentdatauppsättning för att utveckla mycket funktionellt OCR för AI- och ML-modeller. Vår specialiserade process av OCR hjälper till att utveckla optimerade lösningar för kunder.
Vi tillhandahåller omfattande och tillförlitliga datauppsättningar som innehåller tusentals olika extraherade data från skannade dokument. Ta kontakt med vår OCR-lösningar experter för att veta hur vi tillhandahåller skalbara, prisvärda och kundspecifika datauppsättningar.