
Denna metod hjälper AI:n att veta när man ska undvika vissa frågor. Den lär sig att avvisa förfrågningar som involverar skadligt innehåll som våld eller diskriminering.
Ett välkänt exempel på en modell som använder RLHF är OpenAI:s ChatGPT. Denna modell använder mänsklig feedback för att förbättra svaren och göra dem mer relevanta och ansvarsfulla.
Steg för förstärkningsinlärning med mänsklig feedback
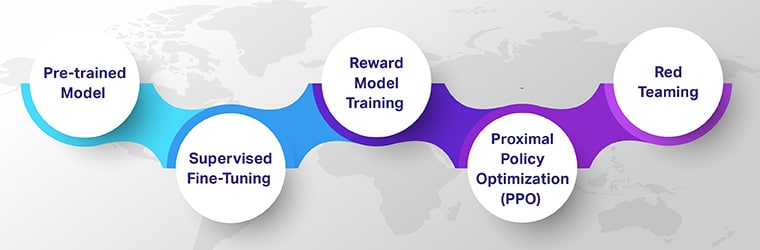
Reinforcement Learning with Human Feedback (RLHF) säkerställer att AI-modeller är tekniskt skickliga, etiskt sunda och kontextuellt relevanta. Titta närmare på de fem nyckelstegen i RLHF som utforskar hur de bidrar till att skapa sofistikerade, människostyrda AI-system.
Börjar med en förutbildad modell
RLHF-resan börjar med en förutbildad modell, ett grundläggande steg i Human-in-the-Loop Machine Learning. Dessa modeller, som ursprungligen tränades på omfattande datauppsättningar, har en bred förståelse av språk eller andra grundläggande uppgifter men saknar specialisering.
Utvecklare börjar med en förutbildad modell och får en betydande fördel. Dessa modeller har redan lärt sig från stora mängder data. Det hjälper dem att spara tid och resurser i den inledande utbildningsfasen. Detta steg skapar förutsättningar för mer fokuserad och specifik träning som följer.
Övervakad finjustering
Det andra steget innebär Supervised finjustering, där den förtränade modellen genomgår ytterligare utbildning på en specifik uppgift eller domän. Detta steg kännetecknas av att använda märkt data, vilket hjälper modellen att generera mer exakta och kontextuellt relevanta utdata.
Denna finjusteringsprocess är ett utmärkt exempel på mänskligt guidad AI-träning, där mänskligt omdöme spelar en viktig roll för att styra AI mot önskade beteenden och reaktioner. Utbildare måste noggrant välja ut och presentera domänspecifika data för att säkerställa att AI:n anpassar sig till nyanserna och specifika kraven för den aktuella uppgiften.
Belöningsmodellutbildning
I det tredje steget tränar du en separat modell för att känna igen och belöna önskvärda resultat som AI genererar. Det här steget är centralt för feedbackbaserad AI-inlärning.
Belöningsmodellen utvärderar AI:s resultat. Den tilldelar poäng baserat på kriterier som relevans, noggrannhet och anpassning till önskade resultat. Dessa poäng fungerar som feedback och vägleder AI mot att producera svar av högre kvalitet. Denna process möjliggör en mer nyanserad förståelse av komplexa eller subjektiva uppgifter där tydliga instruktioner kan vara otillräckliga för effektiv träning.
Reinforcement Learning via Proximal Policy Optimization (PPO)
Därefter genomgår AI Reinforcement Learning via Proximal Policy Optimization (PPO), en sofistikerad algoritmisk metod för interaktiv maskininlärning.
PPO låter AI lära sig av direkt interaktion med sin omgivning. Den förfinar sin beslutsprocess genom belöningar och straff. Denna metod är särskilt effektiv vid inlärning och anpassning i realtid, eftersom den hjälper AI:n att förstå konsekvenserna av dess handlingar i olika scenarier.
PPO är avgörande för att lära AI att navigera i komplexa, dynamiska miljöer där de önskade resultaten kan utvecklas eller vara svåra att definiera.
Röd teaming
Det sista steget innebär rigorösa tester av AI-systemet i verkligheten. Här finns en mångfaldig grupp utvärderare, känd som "rött lag,' utmana AI:n med olika scenarier. De testar dess förmåga att svara korrekt och lämpligt. Den här fasen säkerställer att AI:n kan hantera verkliga applikationer och oförutsedda situationer.
Red Teaming testar AI:s tekniska skicklighet och etiska och kontextuella sundhet. De säkerställer att det fungerar inom acceptabla moraliska och kulturella gränser.
Under dessa steg betonar RLHF vikten av mänskligt engagemang i varje steg av AI-utveckling. Från att vägleda den inledande utbildningen med noggrant utvalda data till att ge nyanserad feedback och rigorösa tester i verkligheten, mänsklig input är en integrerad del av att skapa AI-system som är intelligenta, ansvarsfulla och anpassade till mänskliga värderingar och etik.
Slutsats
Reinforcement Learning with Human Feedback (RLHF) visar en ny era inom AI eftersom den blandar mänskliga insikter med maskininlärning för mer etiska, exakta AI-system.
RLHF lovar att göra AI mer empatisk, inkluderande och innovativ. Det kan ta itu med fördomar och förbättra problemlösningen. Det kommer att förändra områden som hälsovård, utbildning och kundservice.
Att förfina detta tillvägagångssätt kräver dock kontinuerliga ansträngningar för att säkerställa effektivitet, rättvisa och etisk anpassning.


