
Nyckeln till att övervinna AI-utvecklingshinder: mer pålitlig data
Idag har den genomsnittliga personen nu miljontals gånger mer datorkraft i fickan än NASA var tvungen att dra av månlandningen 1969. Samma allestädes närvarande enhet som bekvämt visar ett överflöd av datorkraft uppfyller också en annan förutsättning för AI: s guldålder: ett överflöd av data. Enligt insikter från forskningsgruppen Information Overload skapades 90% av världens data under de senaste två åren. Nu när den exponentiella tillväxten i datorkraft äntligen har konvergerat med lika meteorisk tillväxt i datagenereringen exploderar AI-innovationer så mycket att vissa experter tror kommer att starta en fjärde industriella revolutionen.
Data från National Venture Capital Association tyder på att AI-sektorn såg rekordhöga investeringar på 6.9 miljarder dollar under första kvartalet 2020. Det är inte svårt att se potentialen i AI-verktyg eftersom den redan utnyttjas runt omkring oss. Några av de mer synliga användningsfall för AI-produkter är rekommendationsmotorerna bakom våra favoritapplikationer som Spotify och Netflix. Även om det är kul att upptäcka en ny artist att lyssna på eller en ny TV-show att titta på, är dessa implementeringar ganska låga. Andra algoritmer bedömer testresultat - delvis bestämmer var studenter antas till college - och fortfarande andra siktar igenom kandidatresuméer och bestämmer vilka sökande som får ett visst jobb. Vissa AI-verktyg kan till och med få liv-eller-dödsimplikationer, till exempel AI-modellen som skärmar för bröstcancer (som överträffar läkare).
Trots en stadig tillväxt i både verkliga exempel på AI-utveckling och antalet nystartade företag som kämpar för att skapa nästa generation av transformationsverktyg kvarstår utmaningar för effektiv utveckling och implementering. I synnerhet är AI-utdata bara så exakt som ingången tillåter, vilket innebär att kvalitet är av största vikt.

Navigera efter komplexa krav på efterlevnad
Som om det inte var svårt att hitta kvalitetsdata, är vissa av de branscher som står för att få ut mesta möjliga av innovationer om AI-data också de mest reglerade. Hälsovård är kanske det bästa exemplet, och medan en undersökning från HIT Infrastructure fann att 91% av industrins insiders tror att tekniken skulle kunna förbättra tillgången till vård, optimeras den optimismen av det faktum att 75% ser det som ett hot mot patientsäkerhet och integritet - och patienter är inte de enda i riskzonen.
De omfattande regler som antagits genom Health Insurance Portability and Accountability Act skär nu med olika lokala dataöverensstämmelseshinder, såsom Europas allmänna dataskyddsförordning, California Consumer Privacy Act i USA och Persondataskyddslagen i Singapore. Dessa lokala föreskrifter kommer att förenas med många fler, och när telehälsa framstår som en viktigare källa till hälso- och sjukvårdsdata är det troligt att förordningar kommer att få ett ännu snävare grepp om patientdata under transport. Som ett resultat kommer Shaips säkra och kompatibla molnplattform att visa sig vara ett ännu mer värdefullt sätt att samla in och få tillgång till vårddata för att utbilda AI-produkter.
Personligt identifierbar information kan utgöra ett betydande hot mot din AI-utveckling, men även en helt kompatibel implementering är i fara om den inte kan leverera den typ av exakta resultat som bara kommer med olika träningsdata. En studie från 2020 i Journal of the American Medical Association visade att maskininlärningsalgoritmer inom det medicinska området oftast utbildas med data från patienter i Kalifornien, New York och Massachusetts. Med tanke på att dessa patienter representerar mindre än en femtedel av USA: s befolkning, för att inte säga något om resten av världen, är det svårt att föreställa sig hur dessa modeller kan ge allt annat än partiska resultat.

 Shaip erkänner svårigheten att säkra kompatibel, geografiskt skiftande information och erbjuder licensierad vårdinformation från ett brett spektrum av regioner som specifikt är samlade med syftet att konstruera korrekta algoritmer. Dessa data kommer i form av text, till exempel medicinska register eller kravinformation, medicinsk diagnostisk avbildning som CT-skanningar, ljud som talade anteckningar från läkare eller samtal mellan läkare och patienter, och till och med video från MR-resultat. Det avidentifieras också och anonymiseras, vilket skyddar din organisation från både de etiska och ekonomiska konsekvenserna som kan följa en överträdelse av något av det ökande antalet regler som styr data av både nationellt och internationellt ursprung.
Shaip erkänner svårigheten att säkra kompatibel, geografiskt skiftande information och erbjuder licensierad vårdinformation från ett brett spektrum av regioner som specifikt är samlade med syftet att konstruera korrekta algoritmer. Dessa data kommer i form av text, till exempel medicinska register eller kravinformation, medicinsk diagnostisk avbildning som CT-skanningar, ljud som talade anteckningar från läkare eller samtal mellan läkare och patienter, och till och med video från MR-resultat. Det avidentifieras också och anonymiseras, vilket skyddar din organisation från både de etiska och ekonomiska konsekvenserna som kan följa en överträdelse av något av det ökande antalet regler som styr data av både nationellt och internationellt ursprung.
Att övervinna hinder för AI-utveckling
AI-utvecklingsinsatser inkluderar betydande hinder oavsett i vilken bransch de äger rum, och processen att komma från en genomförbar idé till en framgångsrik produkt är fylld med svårigheter. Mellan utmaningarna med att skaffa rätt data och behovet av att anonymisera det för att följa alla relevanta regler kan det kännas som att det faktiskt är att konstruera och utbilda en algoritm.
För att ge din organisation alla fördelar som behövs för att utforma en banbrytande ny AI-utveckling, vill du överväga att samarbeta med ett företag som Shaip. Chetan Parikh och Vatsal Ghiya grundade Shaip för att hjälpa företag att konstruera de lösningar som kan förändra vården i USA. Efter mer än 16 års verksamhet har vårt företag vuxit till att omfatta mer än 600 teammedlemmar, och vi har arbetat med hundratals kunder att göra övertygande idéer till AI-lösningar.
Med våra medarbetare, processer och plattformar som arbetar för din organisation kan du omedelbart låsa upp följande fyra fördelar och katapultera ditt projekt mot en framgångsrik avslutning:
1. Förmågan att befria dina dataforskare
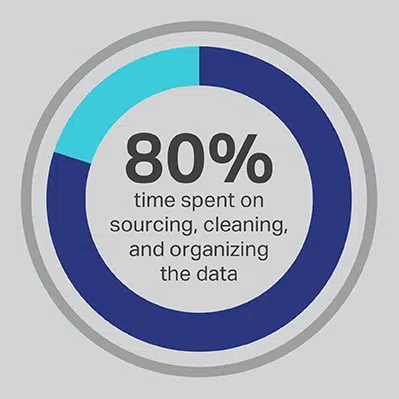
Det går inte att komma runt att AI -utvecklingsprocessen tar en betydande investering i tid, men du kan alltid optimera de funktioner som ditt team lägger mest tid på att utföra. Du anlitade dina datavetenskapare eftersom de är experter på utveckling av avancerade algoritmer och maskininlärningsmodeller, men forskningen visar konsekvent att dessa arbetare faktiskt lägger ner 80% av sin tid på att skaffa, städa och organisera data som driver projektet. Mer än tre fjärdedelar (76%) av dataforskare rapporterar att dessa vardagliga datainsamlingsprocesser också råkar vara deras minst favoritdelar i jobbet, men behovet av kvalitetsdata lämnar bara 20% av sin tid för faktisk utveckling, vilket är det mest intressanta och intellektuellt stimulerande arbetet för många datavetenskapare. Genom att skaffa data via en tredjepartsleverantör som Shaip kan ett företag låta sina dyra och begåvade dataingenjörer lägga ut sitt arbete som dataloppare och istället lägga sin tid på delar av AI-lösningar där de kan producera mest värde.
2. Förmågan att uppnå bättre resultat
 Många AI-utvecklingsledare bestämmer sig för att använda data med öppen källkod eller masskällor för att minska kostnaderna, men det här beslutet kostar nästan alltid mer på lång sikt. Dessa typer av data är tillgängliga, men de kan inte matcha kvaliteten på noggrant samlade datamängder. I synnerhet övermängdsdata är fyllda med fel, utelämnanden och felaktigheter, och även om dessa problem ibland kan ordnas under utvecklingsprocessen under dina ingenjörers vakna ögon, krävs det ytterligare iterationer som inte skulle vara nödvändiga om du började med högre -kvalitetsdata från början.
Många AI-utvecklingsledare bestämmer sig för att använda data med öppen källkod eller masskällor för att minska kostnaderna, men det här beslutet kostar nästan alltid mer på lång sikt. Dessa typer av data är tillgängliga, men de kan inte matcha kvaliteten på noggrant samlade datamängder. I synnerhet övermängdsdata är fyllda med fel, utelämnanden och felaktigheter, och även om dessa problem ibland kan ordnas under utvecklingsprocessen under dina ingenjörers vakna ögon, krävs det ytterligare iterationer som inte skulle vara nödvändiga om du började med högre -kvalitetsdata från början.
Att förlita sig på öppen källkodsdata är en annan vanlig genväg som kommer med sin egen uppsättning fallgropar. Brist på differentiering är en av de största problemen, eftersom en algoritm som tränas med öppen källkod är lättare att replikera än en som bygger på licensierade datamängder. Genom att gå den här vägen bjuder du in konkurrens från andra deltagare i utrymmet som kan underskatta dina priser och ta marknadsandelar när som helst. När du förlitar dig på Shaip får du tillgång till de högkvalitativa uppgifterna som samlats av en skicklig hanterad arbetskraft, och vi kan ge dig en exklusiv licens för en anpassad datamängd som hindrar konkurrenter från att enkelt återskapa din hårt vunna immateriella egendom.
3. Tillgång till erfarna proffs
 Även om din interna lista innehåller skickliga ingenjörer och begåvade datavetare, kan dina AI-verktyg dra nytta av den visdom som bara kommer genom erfarenhet. Våra ämnesexperter har tagit fram en rad AI-implementeringar inom sina områden och lärt sig värdefulla lärdomar på vägen, och deras enda mål är att hjälpa dig att uppnå dina.
Även om din interna lista innehåller skickliga ingenjörer och begåvade datavetare, kan dina AI-verktyg dra nytta av den visdom som bara kommer genom erfarenhet. Våra ämnesexperter har tagit fram en rad AI-implementeringar inom sina områden och lärt sig värdefulla lärdomar på vägen, och deras enda mål är att hjälpa dig att uppnå dina.
Med domenexperter som identifierar, organiserar, kategoriserar och märker data för dig vet du att informationen som används för att träna din algoritm kan ge bästa möjliga resultat. Vi utför också regelbunden kvalitetssäkring för att säkerställa att data uppfyller högsta standard och kommer att fungera som avsett inte bara i ett labb utan också i en verklig situation.
4. En accelererad tidslinje för utveckling
AI-utveckling sker inte över natten, men det kan hända snabbare när du samarbetar med Shaip. Intern datainsamling och anteckning skapar en betydande operativ flaskhals som håller kvar resten av utvecklingsprocessen. Att arbeta med Shaip ger dig omedelbar tillgång till vårt stora bibliotek med färdiga data, och våra experter kommer att kunna skaffa alla typer av ytterligare ingångar du behöver med vår djupa branschkunskap och vårt globala nätverk. Utan bördan med inköp och anteckningar kan ditt team börja arbeta med den faktiska utvecklingen direkt, och vår träningsmodell kan hjälpa till att identifiera tidiga felaktigheter för att minska de iterationer som krävs för att nå noggrannhetsmålen.
Om du inte är redo att lägga ut alla aspekter av din datahantering, erbjuder Shaip också en molnbaserad plattform som hjälper team att producera, ändra och kommentera olika typer av data mer effektivt, inklusive stöd för bilder, video, text och ljud . ShaipCloud innehåller en mängd olika intuitiva validerings- och arbetsflödesverktyg, till exempel en patenterad lösning för att spåra och övervaka arbetsbelastningar, ett transkriptionsverktyg för att transkribera komplexa och svåra ljudinspelningar och en kvalitetskontrollkomponent för att säkerställa kompromisslös kvalitet. Bäst av allt är att den är skalbar så att den kan växa när de olika kraven i ditt projekt ökar.
Åldern för AI-innovation har precis börjat, och vi kommer att se otroliga framsteg och innovationer under de kommande åren som har potential att omforma hela industrier eller till och med förändra samhället som helhet. På Shaip vill vi använda vår expertis för att fungera som en transformerande kraft och hjälpa de mest revolutionerande företagen i världen att utnyttja kraften i AI-lösningar för att uppnå ambitiösa mål.
Vi har djup erfarenhet av vårdapplikationer och konversations-AI, men vi har också nödvändiga färdigheter för att träna modeller för nästan alla typer av applikationer. För mer information om hur Shaip kan hjälpa dig att ta ditt projekt från idé till implementering, ta en titt på de många resurserna som finns på vår webbplats eller kontakta oss idag.
