

Vad är stora språkmodeller?
Large Language Models (LLM) är avancerade system för artificiell intelligens (AI) designade för att bearbeta, förstå och generera människoliknande text. De är baserade på tekniker för djupinlärning och utbildade på massiva datauppsättningar, som vanligtvis innehåller miljarder ord från olika källor som webbplatser, böcker och artiklar. Denna omfattande utbildning gör det möjligt för LLM:er att förstå nyanserna av språk, grammatik, sammanhang och till och med vissa aspekter av allmän kunskap.
Vissa populära LLMs, som OpenAI:s GPT-3, använder en typ av neurala nätverk som kallas en transformator, som gör att de kan hantera komplexa språkuppgifter med anmärkningsvärd skicklighet. Dessa modeller kan utföra ett brett utbud av uppgifter, såsom:
- Besvarar frågor
- Sammanfattande text
- Översätta språk
- Generera innehåll
- Till och med engagera sig i interaktiva konversationer med användare
När LLM fortsätter att utvecklas har de stor potential för att förbättra och automatisera olika applikationer inom olika branscher, från kundservice och innehållsskapande till utbildning och forskning. Men de väcker också etiska och samhälleliga problem, såsom partiskt beteende eller missbruk, som måste åtgärdas när tekniken går framåt.

Populära exempel på stora språkmodeller
Här är några framträdande exempel på LLM:er som används i stor utsträckning i olika branschvertikaler:
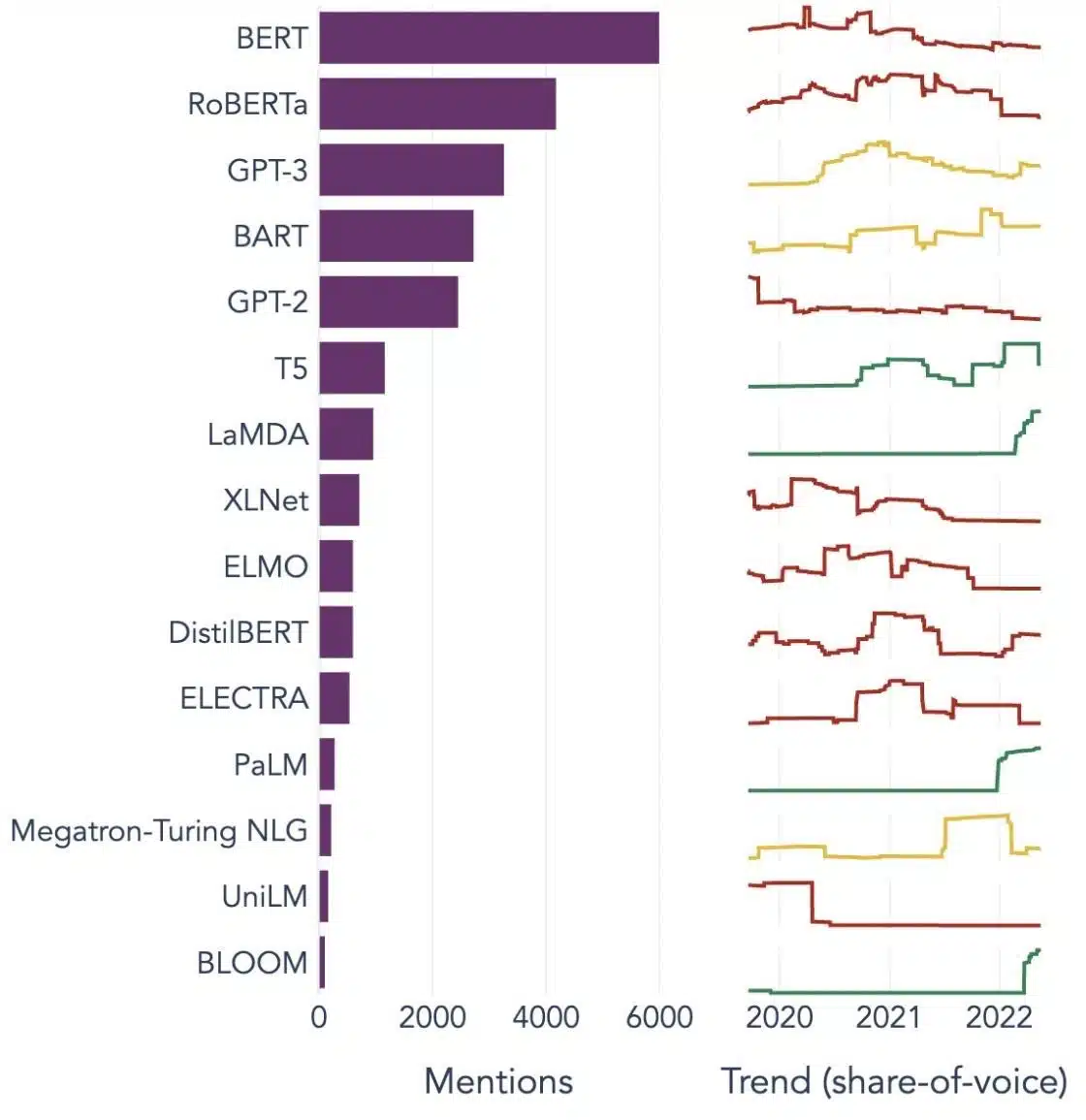
Bild Källa: Mot datavetenskap
Hur tränas LLM-modeller?
Att träna stora språkmodeller (LLM) är en bra bedrift som involverar flera avgörande steg. Här är en förenklad, steg-för-steg genomgång av processen:
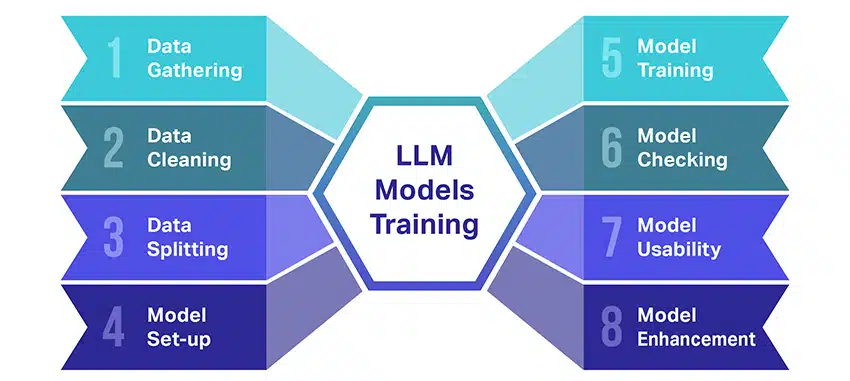
- Samla in textdata: Att träna en LLM börjar med insamlingen av en stor mängd textdata. Dessa data kan komma från böcker, webbplatser, artiklar eller sociala medieplattformar. Syftet är att fånga det mänskliga språkets rika mångfald.
- Rensa upp data: Råtextdata städas sedan i en process som kallas förbearbetning. Detta inkluderar uppgifter som att ta bort oönskade tecken, bryta ner texten i mindre delar som kallas tokens och få det hela till ett format som modellen kan arbeta med.
- Dela upp data: Därefter delas rena data upp i två uppsättningar. En uppsättning, träningsdata, kommer att användas för att träna modellen. Den andra uppsättningen, valideringsdata, kommer att användas senare för att testa modellens prestanda.
- Konfigurera modellen: Strukturen för LLM, känd som arkitekturen, definieras sedan. Det handlar om att välja typ av neurala nätverk och bestämma olika parametrar, såsom antalet lager och dolda enheter inom nätverket.
- Utbildning av modellen: Själva träningen börjar nu. LLM-modellen lär sig genom att titta på träningsdata, göra förutsägelser baserat på vad den har lärt sig hittills och sedan justera sina interna parametrar för att minska skillnaden mellan dess förutsägelser och den faktiska data.
- Kontrollerar modellen: LLM-modellens inlärning kontrolleras med hjälp av valideringsdata. Detta hjälper till att se hur bra modellen presterar och att justera modellens inställningar för bättre prestanda.
- Använda modellen: Efter utbildning och utvärdering är LLM-modellen redo att användas. Den kan nu integreras i applikationer eller system där den kommer att generera text baserat på nya indata som den har getts.
- Förbättra modellen: Slutligen finns det alltid utrymme för förbättringar. LLM-modellen kan förfinas ytterligare över tid, med hjälp av uppdaterad data eller justering av inställningar baserat på feedback och verklig användning.
Kom ihåg att denna process kräver betydande beräkningsresurser, såsom kraftfulla bearbetningsenheter och stor lagring, samt specialiserad kunskap inom maskininlärning. Det är därför det vanligtvis görs av dedikerade forskningsorganisationer eller företag med tillgång till nödvändig infrastruktur och expertis.
Förlitar sig LLM på övervakat eller oövervakat lärande?
Stora språkmodeller tränas vanligtvis med en metod som kallas övervakat lärande. Enkelt uttryckt betyder det att de lär sig av exempel som visar dem rätt svar.
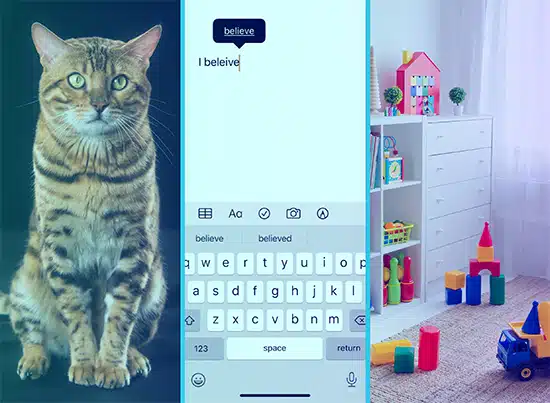 Föreställ dig att du lär ett barn ord genom att visa dem bilder. Du visar dem en bild av en katt och säger "katt", och de lär sig att associera den bilden med ordet. Det är så övervakat lärande fungerar. Modellen får massor av text (”bilderna”) och motsvarande utdata (”orden”), och den lär sig att matcha dem.
Föreställ dig att du lär ett barn ord genom att visa dem bilder. Du visar dem en bild av en katt och säger "katt", och de lär sig att associera den bilden med ordet. Det är så övervakat lärande fungerar. Modellen får massor av text (”bilderna”) och motsvarande utdata (”orden”), och den lär sig att matcha dem.
Så om du matar en LLM med en mening försöker den förutsäga nästa ord eller fras baserat på vad den har lärt sig från exemplen. På så sätt lär den sig hur man skapar text som är vettig och passar sammanhanget.
Som sagt, ibland använder LLMs också lite oövervakat lärande. Det är som att låta barnet utforska ett rum fullt av olika leksaker och lära sig om dem på egen hand. Modellen tittar på omärkta data, inlärningsmönster och strukturer utan att få de "rätta" svaren.
Övervakad inlärning använder data som har märkts med in- och utdata, i motsats till oövervakad inlärning, som inte använder märkt utdata.
I ett nötskal utbildas LLMs huvudsakligen med hjälp av övervakat lärande, men de kan också använda oövervakat lärande för att förbättra sin förmåga, till exempel för utforskande analys och dimensionsreduktion.
Vilken datavolym (i GB) krävs för att träna en stor språkmodell?
En värld av möjligheter för taldataigenkänning och röstapplikationer är enorm, och de används i flera branscher för en uppsjö av applikationer.
Att träna en stor språkmodell är inte en process som passar alla, särskilt när det kommer till den data som behövs. Det beror på en massa saker:
- Modellens design.
- Vilket jobb behöver den göra?
- Typen av data du använder.
- Hur bra vill du att den ska prestera?
Som sagt, utbildning av LLM kräver vanligtvis en enorm mängd textdata. Men hur massiva pratar vi om? Tja, tänk långt bortom gigabyte (GB). Vi tittar vanligtvis på terabyte (TB) eller till och med petabyte (PB) data.
Tänk på GPT-3, en av de största LLM:erna som finns. Det tränas på 570 GB textdata. Mindre LLM kan behöva mindre – kanske 10-20 GB eller till och med 1 GB gigabyte – men det är fortfarande mycket.

Men det handlar inte bara om storleken på datan. Kvalitet spelar också roll. Datan måste vara ren och varierad för att modellen ska lära sig effektivt. Och du kan inte glömma andra viktiga pusselbitar, som den datorkraft du behöver, algoritmerna du använder för träning och hårdvaruinställningen du har. Alla dessa faktorer spelar en stor roll i utbildningen av en LLM.
Uppkomsten av stora språkmodeller: varför de är viktiga
LLM är inte längre bara ett koncept eller ett experiment. De spelar en allt mer avgörande roll i vårt digitala landskap. Men varför händer detta? Vad är det som gör dessa LLM så viktiga? Låt oss fördjupa oss i några nyckelfaktorer.
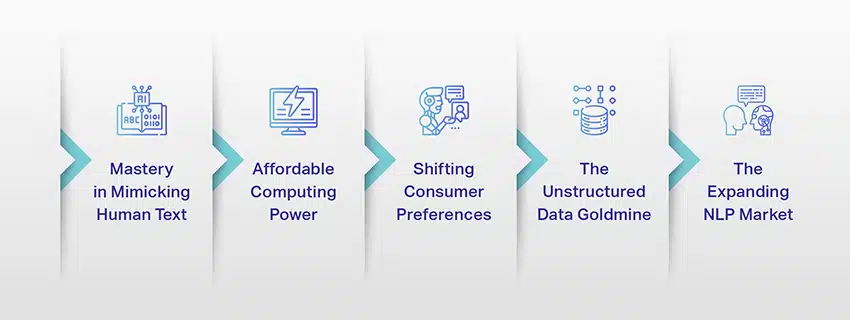
Behärskning av att efterlikna mänsklig text
LLM:er har förändrat sättet vi hanterar språkbaserade uppgifter. Dessa modeller är byggda med robusta maskininlärningsalgoritmer och är utrustade med förmågan att förstå nyanserna i mänskligt språk, inklusive sammanhang, känslor och till och med sarkasm, till viss del. Denna förmåga att efterlikna mänskligt språk är inte bara en nyhet, den har betydande implikationer.
LLMs avancerade textgenereringsförmåga kan förbättra allt från innehållsskapande till kundtjänstinteraktioner.
Föreställ dig att kunna ställa en komplex fråga till en digital assistent och få ett svar som inte bara är vettigt, utan också är sammanhängande, relevant och levereras i en konversationston. Det är vad LLMs möjliggör. De underblåser en mer intuitiv och engagerande interaktion mellan människa och maskin, berikar användarupplevelser och demokratiserar tillgången till information.
Prisvärd datorkraft
Framväxten av LLM skulle inte ha varit möjlig utan parallell utveckling inom dataområdet. Mer specifikt har demokratiseringen av beräkningsresurser spelat en betydande roll i utvecklingen och antagandet av LLM:er.
Molnbaserade plattformar erbjuder oöverträffad tillgång till högpresterande datorresurser. På så sätt kan även småskaliga organisationer och oberoende forskare träna sofistikerade modeller för maskininlärning.
Dessutom har förbättringar i bearbetningsenheter (som GPU:er och TPU:er), i kombination med uppkomsten av distribuerad datoranvändning, gjort det möjligt att träna modeller med miljarder parametrar. Denna ökade tillgänglighet för datorkraft möjliggör tillväxt och framgång för LLM, vilket leder till mer innovation och tillämpningar på området.
Ändra konsumentinställningar
Konsumenter idag vill inte bara ha svar; de vill ha engagerande och relaterbar interaktion. När fler människor växer upp med digital teknik, är det uppenbart att behovet av teknik som känns mer naturlig och människolik ökar. LLM erbjuder en oöverträffad möjlighet att möta dessa förväntningar. Genom att generera människoliknande text kan dessa modeller skapa engagerande och dynamiska digitala upplevelser, vilket kan öka användarnas tillfredsställelse och lojalitet. Oavsett om det är AI-chatbots som tillhandahåller kundservice eller röstassistenter som tillhandahåller nyhetsuppdateringar, inleder LLM:er en era av AI som förstår oss bättre.
Den ostrukturerade dataguldgruvan
Ostrukturerad data, som e-postmeddelanden, inlägg på sociala medier och kundrecensioner, är en skattkammare av insikter. Det uppskattas att över 80% av företagsdata är ostrukturerad och växer i en takt av 55% per år. Denna data är en guldgruva för företag om den utnyttjas på rätt sätt.
LLM:er kommer in i bilden här, med deras förmåga att bearbeta och förstå sådan data i stor skala. De kan hantera uppgifter som sentimentanalys, textklassificering, informationsextraktion med mera, vilket ger värdefulla insikter.
Oavsett om det handlar om att identifiera trender från inlägg på sociala medier eller mäta kundernas sentiment från recensioner, hjälper LLM företag att navigera i den stora mängden ostrukturerad data och fatta datadrivna beslut.
Den expanderande NLP-marknaden
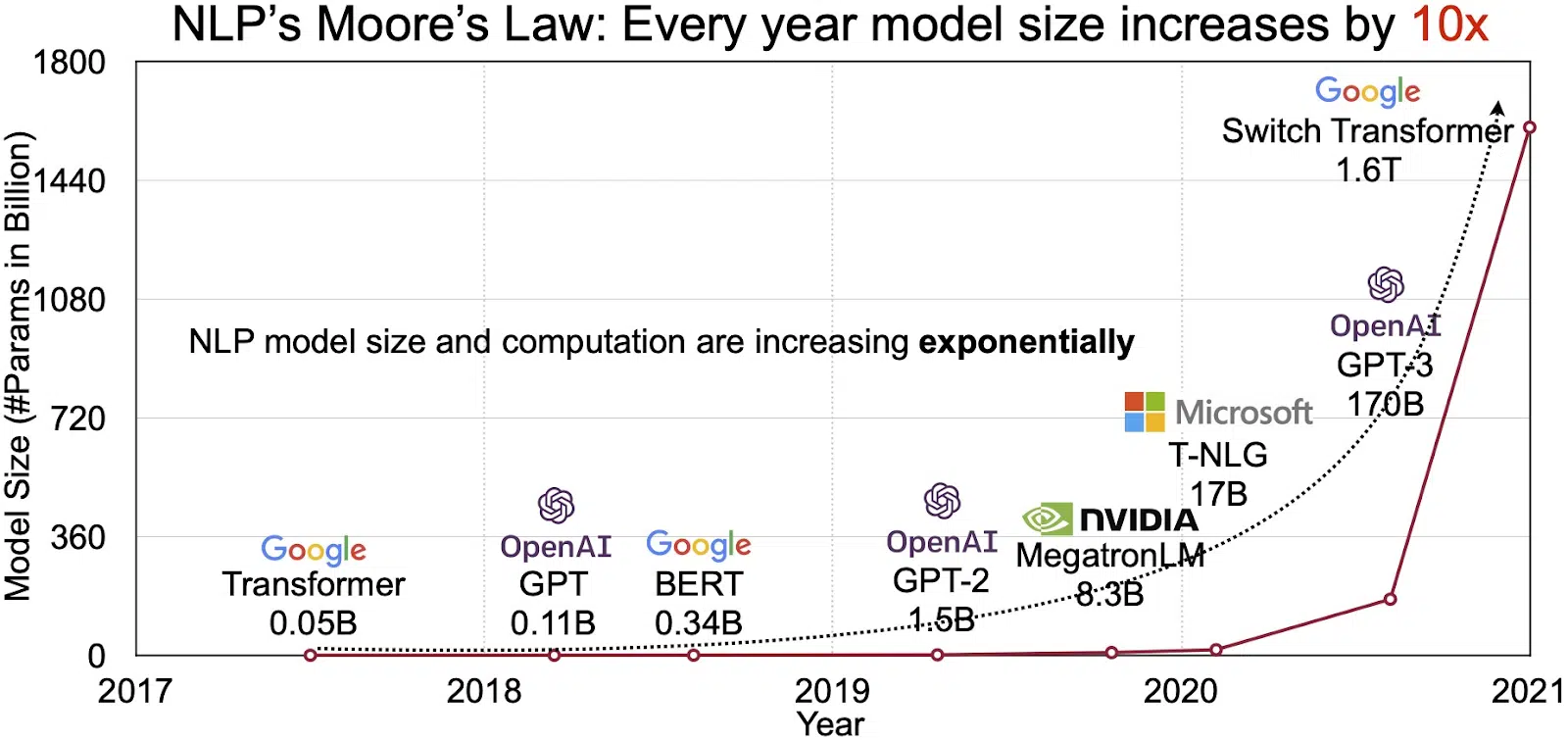
LLMs potential återspeglas i den snabbt växande marknaden för naturlig språkbehandling (NLP). Analytiker räknar med att NLP-marknaden kan expandera från 11 miljarder dollar 2020 till över 35 miljarder dollar 2026. Men det är inte bara marknadsstorleken som växer. Modellerna i sig växer också, både i fysisk storlek och i antal parametrar de hanterar. Utvecklingen av LLM:er under åren, som visas i figuren nedan (bildkälla: länk), understryker deras ökande komplexitet och kapacitet.
Populära användningsfall av stora språkmodeller
Här är några av de vanligaste och vanligaste användningsfallen av LLM:
- Generera text på naturligt språk: Large Language Models (LLM) kombinerar kraften hos artificiell intelligens och beräkningslingvistik för att självständigt producera texter på naturligt språk. De kan tillgodose olika användarbehov som att skriva artiklar, skapa låtar eller delta i konversationer med användare.
- Översättning genom maskiner: LLM:er kan effektivt användas för att översätta text mellan alla språkpar. Dessa modeller utnyttjar algoritmer för djupinlärning som återkommande neurala nätverk för att förstå den språkliga strukturen för både käll- och målspråk, och därigenom underlätta översättningen av källtexten till det önskade språket.
- Skapa originalinnehåll: LLM har öppnat vägar för maskiner att generera sammanhängande och logiskt innehåll. Detta innehåll kan användas för att skapa blogginlägg, artiklar och andra typer av innehåll. Modellerna utnyttjar sin djupa djuplärande erfarenhet för att formatera och strukturera innehållet på ett nytt och användarvänligt sätt.
- Analysera känslor: En spännande tillämpning av stora språkmodeller är sentimentanalys. I detta är modellen tränad att känna igen och kategorisera känslomässiga tillstånd och känslor som finns i den kommenterade texten. Programvaran kan identifiera känslor som positivitet, negativitet, neutralitet och andra intrikata känslor. Detta kan ge värdefulla insikter om kundfeedback och synpunkter på olika produkter och tjänster.
- Förstå, sammanfatta och klassificera text: LLM:er etablerar en hållbar struktur för AI-programvara för att tolka texten och dess sammanhang. Genom att instruera modellen att förstå och granska stora mängder data gör LLM-modeller det möjligt för AI-modeller att förstå, sammanfatta och till och med kategorisera text i olika former och mönster.
- Besvarar frågor: Stora språkmodeller utrustar QA-system (Question Answering) med förmågan att korrekt uppfatta och svara på en användares naturliga språkfråga. Populära exempel på detta användningsfall inkluderar ChatGPT och BERT, som undersöker sammanhanget för en fråga och sållar igenom en stor samling texter för att ge relevanta svar på användarfrågor.

Ordspråksmärkning (POS).
Ord i meningar är taggade med sin grammatiska funktion, såsom verb, substantiv, adjektiv, etc. Denna process hjälper modellen att förstå grammatiken och kopplingarna mellan ord.

Namngiven entitetsigenkänning (NER)
Namngivna enheter som organisationer, platser och personer i en mening är markerade. Denna övning hjälper modellen att tolka den semantiska betydelsen av ord och fraser och ger mer exakta svar.

Sentimentanalys
Textdata tilldelas sentimentetiketter som positiv, neutral eller negativ, vilket hjälper modellen att förstå meningarnas känslomässiga underton. Det är särskilt användbart för att svara på frågor som involverar känslor och åsikter.
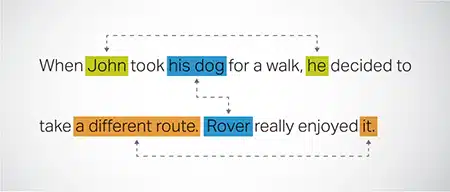
Coreference Resolution
Identifiera och lösa fall där samma enhet refereras till i olika delar av en text. Detta steg hjälper modellen att förstå meningen med sammanhanget, vilket leder till sammanhängande svar.
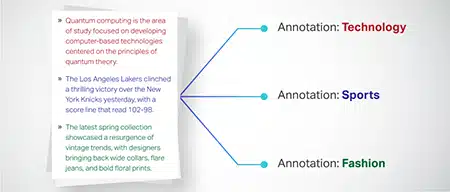
Textklassificering
Textdata kategoriseras i fördefinierade grupper som produktrecensioner eller nyhetsartiklar. Detta hjälper modellen att urskilja genren eller ämnet för texten och genererar mer relevanta svar.
Shaips erbjudande
Shaip erbjuder ett brett utbud av tjänster för att hjälpa organisationer att hantera, analysera och få ut det mesta av sin data.
Datawebbskrapning
En nyckeltjänst som erbjuds av Shaip är dataskrapning. Detta innebär extrahering av data från domänspecifika webbadresser. Genom att använda automatiserade verktyg och tekniker kan Shaip snabbt och effektivt skrapa stora mängder data från olika webbplatser, produktmanualer, teknisk dokumentation, onlineforum, onlinerecensioner, kundtjänstdata, branschreglerande dokument etc. Denna process kan vara ovärderlig för företag när samla in relevant och specifik data från en mängd källor.

Maskinöversättning
Utveckla modeller med hjälp av omfattande flerspråkiga datauppsättningar parade med motsvarande transkriptioner för att översätta text över olika språk. Denna process hjälper till att undanröja språkliga hinder och främjar tillgängligheten till information.
Taxonomy Extraction & Creation
Shaip kan hjälpa till med taxonomiextraktion och skapande. Detta innebär att klassificera och kategorisera data i ett strukturerat format som återspeglar relationerna mellan olika datapunkter. Detta kan vara särskilt användbart för företag att organisera sin data, vilket gör den mer tillgänglig och lättare att analysera. Till exempel, i en e-handelsverksamhet kan produktdata kategoriseras baserat på produkttyp, varumärke, pris, etc., vilket gör det lättare för kunder att navigera i produktkatalogen.
Datainsamling
Våra datainsamlingstjänster tillhandahåller kritisk verklig eller syntetisk data som behövs för att träna generativa AI-algoritmer och förbättra noggrannheten och effektiviteten hos dina modeller. Uppgifterna är opartiska, etiskt och ansvarsfullt inhämtade samtidigt som dataintegritet och säkerhet i åtanke.

Frågor & svar
Question answering (QA) är ett underområde av naturlig språkbehandling som fokuserar på att automatiskt svara på frågor på mänskligt språk. QA-system är utbildade i omfattande text och kod, vilket gör det möjligt för dem att hantera olika typer av frågor, inklusive fakta-, definitions- och åsiktsbaserade. Domänkunskap är avgörande för att utveckla QA-modeller som är skräddarsydda för specifika områden som kundsupport, sjukvård eller försörjningskedja. Generativa QA-metoder gör det dock möjligt för modeller att generera text utan domänkännedom, enbart beroende på sammanhang.
Vårt team av specialister kan noggrant studera omfattande dokument eller manualer för att generera fråga-svar-par, vilket underlättar skapandet av Generativ AI för företag. Detta tillvägagångssätt kan effektivt hantera användarförfrågningar genom att ta fram relevant information från en omfattande korpus. Våra certifierade experter säkerställer produktionen av Q&A-par av högsta kvalitet som spänner över olika ämnen och domäner.

Textsammanfattning
Våra specialister kan destillera omfattande konversationer eller långa dialoger, leverera kortfattade och insiktsfulla sammanfattningar från omfattande textdata.

Textgenerering
Träna modeller med en bred datauppsättning av text i olika stilar, som nyhetsartiklar, skönlitteratur och poesi. Dessa modeller kan sedan generera olika typer av innehåll, inklusive nyhetsartiklar, blogginlägg eller inlägg på sociala medier, och erbjuder en kostnadseffektiv och tidsbesparande lösning för att skapa innehåll.
Taligenkänning
Utveckla modeller som kan förstå talat språk för olika tillämpningar. Detta inkluderar röstaktiverade assistenter, dikteringsprogram och översättningsverktyg i realtid. Processen involverar att använda en omfattande datauppsättning som består av ljudinspelningar av talat språk, parat med deras motsvarande avskrifter.

Produktrekommendationer
Utveckla modeller med hjälp av omfattande datauppsättningar av kundköphistorik, inklusive etiketter som pekar på de produkter som kunderna är benägna att köpa. Målet är att ge exakta förslag till kunderna och därigenom öka försäljningen och öka kundnöjdheten.
Bildtextning
Revolutionera din bildtolkningsprocess med vår toppmoderna, AI-drivna tjänst för bildtextning. Vi ingjuter vitalitet i bilder genom att producera korrekta och kontextuellt meningsfulla beskrivningar. Detta banar väg för innovativa engagemang och interaktionsmöjligheter med ditt visuella innehåll för din publik.

Utbildning av text-till-tal-tjänster
Vi tillhandahåller en omfattande datauppsättning som består av ljudinspelningar av mänskligt tal, perfekt för träning av AI-modeller. Dessa modeller kan generera naturliga och engagerande röster för dina applikationer och på så sätt leverera en distinkt och uppslukande ljudupplevelse för dina användare.



