






Text insamling

Ljud-/talsamling
Textnotering
Ljud- / talanmälan

Texttranskription

Ljud- / taltranskription




Conversational AI / Chatbot Training
Utbildning av digitala assistenter kräver en stor uppsättning kvalitetsdata från olika geografier, språk, dialekter, inställningar och format. På Shaip erbjuder vi utbildningsdata för AI-modeller med Human-in-the-loop som har den nödvändiga kunskapen, domänkunskapen och är väl medvetna om kundens specifika behov.
Känsla / avsikt
Analys
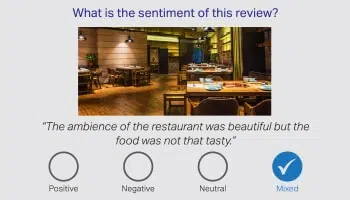
Det sägs med rätta att ord ensam misslyckas med att kommunicera hela historien, och åliggerna ligger på mänskliga kommentatorer för att tolka tvetydigheten på mänskligt språk. Därför är det av yttersta vikt att identifiera känslan hos en kund, baserat på konversationen. Våra språkexperter från olika domäner kan tolka nyanser i produktrecensioner, finansiella nyheter och sociala medier.

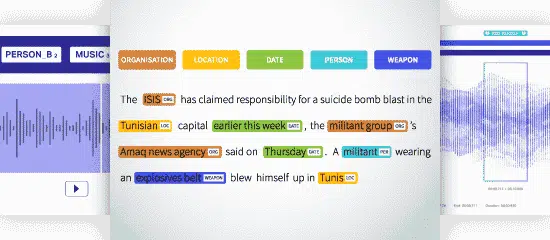
Namngiven entitetsigenkänning (NER)
Named Entity Recognition (NER) är att identifiera, extrahera och klassificera de namngivna enheterna i en text i fördefinierade kategorier. Texten kan kategoriseras som en plats, namn, organisation, produkt, kvantitet, värde, procent osv. Med NER kan du ta upp verkliga frågor som vilka organisationer som nämndes i artikeln etc.
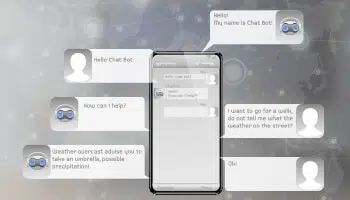
Client Service Automation
Robusta, välutbildade virtuella chatbots eller digitala assistenter har revolutionerat sättet kunderna kommunicerar med säljarna, vilket förbättrat kundupplevelsen betydligt.

Texttranskription
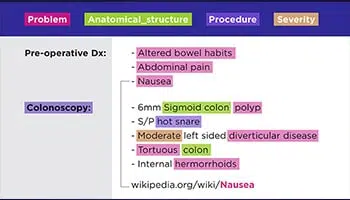
Från läkares handskrivna recept till anteckningar om konferenssamtal, våra specialister kan digitalisera vilken form av data som helst, det vill säga arkiverade dokument, juridiska kontrakt, patientjournaler etc.
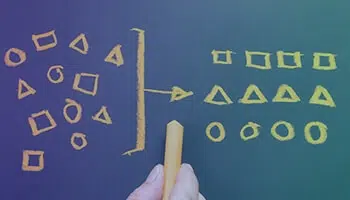
Innehållskategorisering
Kategorisering också känd som klassificering eller märkning är processen att klassificera text i organiserade grupper och märka den, baserat på dess intressanta funktioner.

Ämnesanalys
Ämnesanalys eller ämnesmärkning är att identifiera och extrahera mening från en viss text genom att identifiera återkommande ämnen / teman som övervägs.

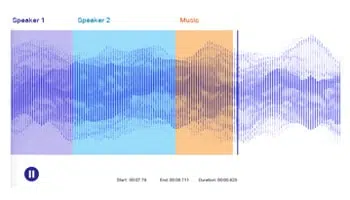
Ljudtranskription
Transkribera tal/podcast/seminarium, ring samtal till text. Dra nytta av människor för att korrekt kommentera ljud-/talfiler för att träna NLP -modeller exakt.

Ljudklassificering
Kategorisera ljud eller yttranden för att klassificera tal / ljud baserat på språk, dialekt, semantik, lexikon etc.

Personer
Dedikerade och utbildade team:
- 30,000+ medarbetare för dataskapande, märkning och kvalitetssäkring
- Godkänd projektledningsteam
- Erfaren produktutvecklingsteam
- Talent Pool Sourcing & Onboarding Team

Behandla
Högsta processeffektivitet säkerställs med:
- Robust 6 Sigma Stage-Gate-process
- Ett dedikerat team med 6 Sigma-svarta bälten - Viktiga processägare och kvalitetskrav
- Kontinuerlig förbättring och återkopplingsslinga

plattform
Den patenterade plattformen erbjuder fördelar:
- Webbaserad end-to-end-plattform
- Oklanderlig kvalitet
- Snabbare TAT
- Sömlös leverans


