



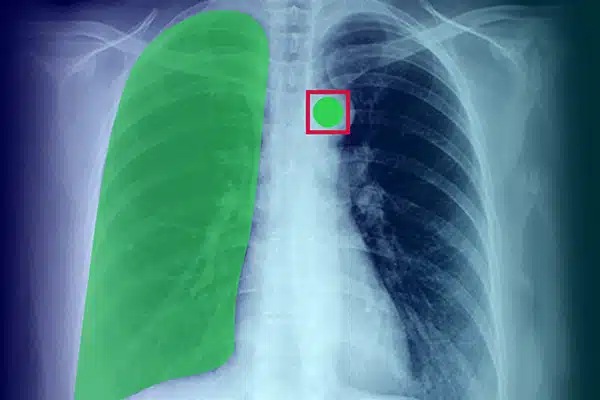
Bildanmärkning
Förbättra medicinsk AI genom att kommentera visuella data från röntgenstrålar, CT-skanningar och MRI. Se till att AI-modeller presterar utmärkt i diagnostik och behandling, vägledd av expertdatamärkning. Få bättre patientresultat med överlägsen bildinsikter.
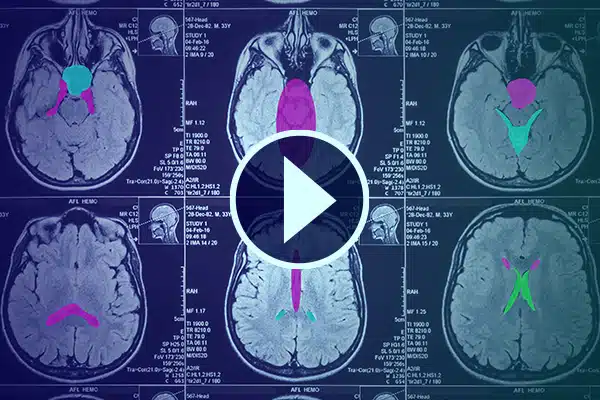
Videonotering
Avancera AI i sjukvården med detaljerad videokommentar. Skärp AI-inlärning med klassificeringar och segmentering i medicinska bilder. Förbättra din kirurgiska AI och patientövervakning för förbättrad sjukvård och diagnostik.
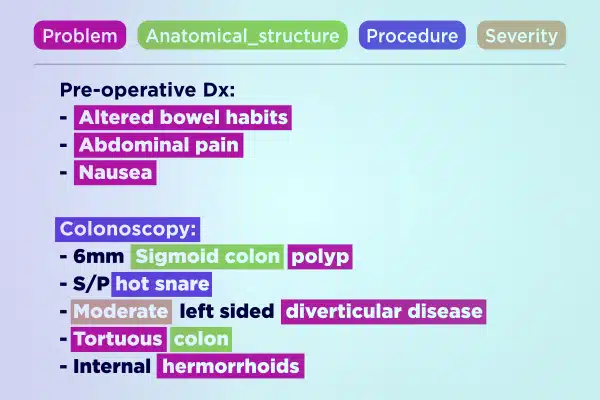
Textnotering
Effektivisera medicinsk AI-utveckling med expertkommentarer i textdata. Analysera och berika snabbt stora textvolymer, från handskrivna anteckningar till försäkringsrapporter. Säkerställ korrekta och handlingsbara insikter för sjukvårdens framsteg.

Ljudanteckning
Utnyttja NLP-expertis för att kommentera och märka medicinsk ljuddata korrekt. Skapa röstassisterade system för sömlös klinisk verksamhet och integrera AI i olika röstaktiverade hälsovårdsprodukter. Förbättra diagnostisk precision med expertljuddatakurering.

Medicinsk kodning
Effektivisera medicinsk dokumentation genom att konvertera den till universella koder med AI medicinsk kodning. Säkerställ noggrannhet, förbättra faktureringseffektiviteten och stödja sömlös leverans av sjukvårdstjänster med banbrytande AI-hjälp vid journalkodning.

Fas 1: Teknisk domänexpertis (Förstå omfattning och anteckningsriktlinjer)

Fas 2: Utbilda lämpliga resurser för projektet

Fas 3: Återkopplingscykel och QA för de kommenterade dokumenten
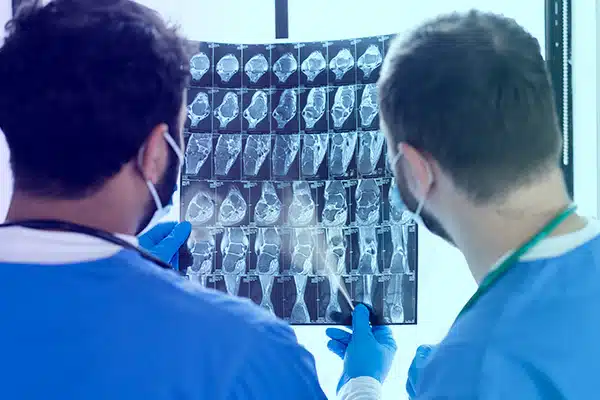
Radiologi
Vår tjänst för röntgenbildkommentarer skärper AI-diagnostik och inkluderar ett extra lager av expertis. Varje röntgen-, MRI- och CT-skanning är noggrant märkt och granskad av en sakkunnig. Detta extra steg i träning och granskning ökar AI:s förmåga att upptäcka avvikelser och sjukdomar. Det förbättrar noggrannheten innan leverans till våra kunder.

Kardiologi
Vår kardiologifokuserade bildkommentar skärper AI-diagnostik. Vi tar in kardiologiska experter som märker komplexa hjärtrelaterade bilder och tränar våra AI-modeller. Innan vi skickar data till kunder granskar dessa specialister varje bild för att säkerställa högsta noggrannhet. Denna process gör det möjligt för AI att upptäcka hjärtsjukdomar mer exakt.
Tandvård
Vår bildkommentartjänst inom tandvården märker tandbilder för att förbättra AI-diagnosverktyg. Genom att noggrant identifiera karies, anpassningsproblem och andra tandtillstånd, ger våra små och medelstora företag AI möjlighet att förbättra patientresultaten och stödja tandläkare i exakt behandlingsplanering och tidig upptäckt.


















Personer
Dedikerade och utbildade team:
- 30,000+ medarbetare för dataskapande, märkning och kvalitetssäkring
- Godkänd projektledningsteam
- Erfaren produktutvecklingsteam
- Talent Pool Sourcing & Onboarding Team

Behandla
Högsta processeffektivitet säkerställs med:
- Robust 6 Sigma Stage-Gate-process
- Ett dedikerat team med 6 Sigma-svarta bälten - Viktiga processägare och kvalitetskrav
- Kontinuerlig förbättring och återkopplingsslinga

plattform
Den patenterade plattformen erbjuder fördelar:
- Webbaserad end-to-end-plattform
- Oklanderlig kvalitet
- Snabbare TAT
- Sömlös leverans



