
Data är supermakten som förändrar det digitala landskapet i dagens värld. Från e-post till inlägg på sociala medier, det finns data överallt. Det är sant att företag aldrig har haft tillgång till så mycket data, men räcker det med tillgång till data? Den rika informationskällan blir värdelös eller föråldrad när den inte bearbetas.
Ostrukturerad text kan vara en rik källa till information, men den kommer inte att vara användbar för företag om inte data organiseras, kategoriseras och analyseras. Ostrukturerad data, såsom text, ljud, videor och sociala medier, uppgår till 80 -90% av all data. Dessutom uppges knappt 18 % av organisationerna dra fördel av sin organisations ostrukturerade data.
Att manuellt sålla igenom terabyte av data som lagras på servrarna är en tidskrävande och ärligt talat omöjlig uppgift. Men med framstegen inom maskininlärning, naturlig språkbehandling och automatisering är det möjligt att strukturera och analysera textdata snabbt och effektivt. Det första steget i dataanalys är textklassificering.
Vad är textklassificering?
Textklassificering eller kategorisering är processen att gruppera text i förutbestämda kategorier eller klasser. Genom att använda denna maskininlärningsmetod kan alla text – dokument, webbfiler, studier, juridiska dokument, medicinska rapporter och mer – kan klassificeras, organiseras och struktureras.
Textklassificering är det grundläggande steget i naturlig språkbehandling som har flera användningsområden för att upptäcka skräppost. Sentimentanalys, avsiktsdetektion, datamärkning och mer.
Möjliga användningsfall av textklassificering
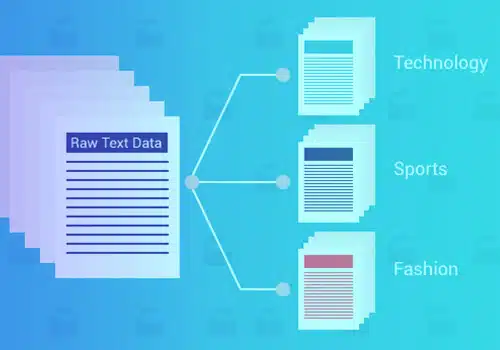 Det finns flera fördelar med att använda maskininlärningstextklassificering, såsom skalbarhet, analyshastighet, konsekvens och möjligheten att fatta snabba beslut baserat på realtidskonversationer.
Det finns flera fördelar med att använda maskininlärningstextklassificering, såsom skalbarhet, analyshastighet, konsekvens och möjligheten att fatta snabba beslut baserat på realtidskonversationer.
När ML-modellen är tränad på AI som automatiskt kategoriserar objekt under förinställda kategorier, kan du snabbt konvertera tillfälliga webbläsare till kunder.
Textklassificeringsprocess
Textklassificeringsprocessen börjar med förbearbetning, val av funktioner, extrahering och klassificering av data.

Förbearbetning
tokenization: Text är uppdelad i mindre och enklare textformer för enkel klassificering.
Normalisering: All text i ett dokument måste vara på samma nivå av förståelse. Vissa former av normalisering inkluderar,
- Upprätthålla grammatiska eller strukturella standarder över hela texten, som att ta bort blanksteg eller skiljetecken. Eller behålla gemener i hela texten.
- Ta bort prefix och suffix från ord och återföra dem till deras grundord.
- Att ta bort stoppord som "och" "är" "det" och fler som inte ger texten mervärde.
Funktionsval
Funktionsval är ett grundläggande steg i textklassificering. Processen syftar till att representera texter med den mest relevanta egenskapen. Funktionsval hjälper till att ta bort irrelevanta data och förbättra noggrannheten.
Funktionsval minskar indatavariabeln i modellen genom att endast använda de mest relevanta data och eliminera brus. Baserat på vilken typ av lösning du söker kan dina AI-modeller designas för att endast välja de relevanta funktionerna från texten.
Särdragsextraktion
Funktionsextraktion är ett valfritt steg som vissa företag tar för att extrahera ytterligare nyckelfunktioner i data. Funktionsextraktion använder flera tekniker, såsom kartläggning, filtrering och klustring. Den främsta fördelen med att använda funktionsextraktion är – det hjälper till att ta bort redundant data och förbättrar hastigheten med vilken ML-modellen utvecklas.
Tagga data till förutbestämda kategorier
Att tagga text till fördefinierade kategorier är det sista steget i textklassificering. Det kan göras på tre olika sätt,
- Manuell märkning
- Regelbaserad matchning
- Inlärningsalgoritmer – Inlärningsalgoritmerna kan vidare klassificeras i två kategorier, såsom övervakad taggning och oövervakad taggning.
- Övervakad inlärning: ML-modellen kan automatiskt anpassa taggarna med befintliga kategoriserade data i övervakad taggning. När kategoriserad data redan finns tillgänglig kan ML-algoritmerna kartlägga funktionen mellan taggarna och texten.
- Oövervakad inlärning: Det händer när det saknas tidigare taggade data. ML-modeller använder klustring och regelbaserade algoritmer för att gruppera liknande texter, till exempel baserat på produktköphistorik, recensioner, personlig information och biljetter. Dessa breda grupper kan analyseras ytterligare för att dra värdefulla kundspecifika insikter som kan användas för att utforma skräddarsydda kundansatser.
Det finns flera användningsfall för textklassificering mellan branscher. Även om insamling, gruppering, klassificering och extrahering av värdefulla insikter från textdata alltid har använts inom flera områden, hittar textklassificering sin potential inom marknadsföring, produktutveckling, kundservice, ledning och administration. Det hjälper företag att få konkurrenskraftig intelligens, marknads- och kundkännedom och fatta databaserade affärsbeslut.
Att utveckla ett effektivt och insiktsfullt textklassificeringsverktyg är inte lätt. Ändå, med Shaip som din datapartner kan du utveckla ett effektivt, skalbart och kostnadseffektivt AI-baserat textklassificeringsverktyg. Vi har massor av noggrant kommenterade och färdiga datauppsättningar som kan anpassas efter din modells unika krav. Vi gör din text till en konkurrensfördel; hör av dig idag.


