
Internet har öppnat dörrarna för människor som fritt kan uttrycka sina åsikter, åsikter och förslag om nästan vad som helst i världen på sociala medier, webbplatser och bloggar. Förutom att uttrycka sina åsikter, påverkar människor (kunder) även andras köpbeslut. Känslan, vare sig den är negativ eller positiv, är avgörande för alla företag eller varumärken som oroar sig för försäljningen av sina produkter eller tjänster.
Att hjälpa företag bryta kommentarerna för affärsbruk är Naturlig språkbehandling. En av fyra företag har planer på att implementera NLP-teknik inom det närmaste året för att styra sina affärsbeslut. Med hjälp av sentimentanalys hjälper NLP företag att få tolkbara insikter från rå och ostrukturerad data.
Åsiktsbrytning eller känsla analys är en NLP-teknik som används för att identifiera den exakta känslan – positiv, negativ eller neutral – i samband med kommentarer och feedback. Med hjälp av NLP analyseras nyckelord i kommentarerna för att avgöra vilka positiva eller negativa ord som finns i sökordet.
Sentiment poängsätts på ett skalningssystem som tilldelar sentimentpoäng till känslor i en text (avgör texten som positiv eller negativ).
Vad är Multilingual Sentiment Analysis?

Som namnet antyder, flerspråkig sentimentanalys är tekniken för att utföra sentimentpoäng för mer än ett språk. Det är dock inte så enkelt. Vår kultur, språk och upplevelser påverkar i hög grad vårt köpbeteende och våra känslor. Utan en god förståelse för användarens språk, sammanhang och kultur är det omöjligt att korrekt förstå användarens avsikter, känslor och tolkningar.
Även om automatisering är svaret på många av våra moderna problem, maskinöversättning programvaran kommer inte att kunna uppfatta nyanserna i språket, vardagsspråk, subtiliteter och kulturella referenser i kommentarerna och recensioner den översätter. ML-verktyget kan ge dig en översättning, men det kanske inte är användbart. Det är anledningen till att flerspråkig sentimentanalys krävs.
Varför behövs flerspråkig sentimentanalys?
De flesta företag använder engelska som kommunikationsmedium, men det används inte av de flesta konsumenter över hela världen.
Enligt Ethnologue talar cirka 13 % av världens befolkning engelska. Dessutom uppger British Council att cirka 25 % av världens befolkning har en anständig förståelse av engelska. Om man ska tro dessa siffror så interagerar en stor del av konsumenterna med varandra och verksamheten på ett annat språk än engelska.
Om huvudsyftet med företag är att behålla sin kundbas intakt och attrahera nya kunder, måste de på nära håll förstå deras kunders åsikter som uttrycks i deras modersmål. Att manuellt granska varje kommentar eller översätta dem till engelska är en besvärlig process som inte kommer att ge effektiva resultat.
En hållbar lösning är att utveckla flerspråkig sentimentanalyssystem som upptäcker och analyserar kunders åsikter, känslor och förslag i sociala medier, forum, undersökningar och mer.
Steg för att utföra flerspråkig sentimentanalys
Sentimentanalys, oavsett om det är på ett enda språk eller flera språk, är en process som kräver tillämpning av maskininlärningsmodeller, naturlig språkbehandling och dataanalystekniker för att extrahera flerspråkig sentiment poängsättning från datan.
Stegen som är involverade i flerspråkig sentimentanalys är
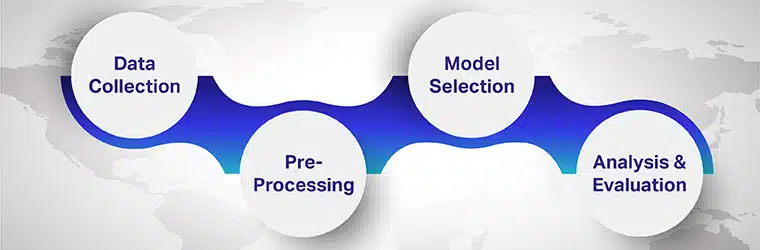
Steg 1: Samla in data
Att samla in data är det första steget i att tillämpa sentimentanalys. Att skapa en flerspråkig sentimentanalysmodell, är det viktigt att skaffa data på en mängd olika språk. Allt kommer att bero på kvaliteten på data som samlas in, kommenteras och märks. Du kan hämta data från API:er, arkiv med öppen källkod och utgivare.
Steg 2: Förbearbetning
Webbdata som samlas in bör rengöras och information hämtas från den. De delar av texten som inte förmedlar någon speciell betydelse, som "det" "är" och mer, bör tas bort. Vidare bör texten grupperas i ordgrupper för att kategoriseras för att förmedla en positiv eller negativ betydelse.
För att förbättra klassificeringskvaliteten bör innehållet rengöras från brus, såsom HTML-taggar, annonser och skript. Språk, lexikon och grammatik som används av människor är olika beroende på det sociala nätverket. Det är viktigt att normalisera sådant innehåll och förbereda det för förbearbetning.
Ett annat kritiskt steg i förbearbetningen är att använda naturlig språkbehandling för att dela meningar, ta bort stoppord, tagga delar av tal, omvandla ord till sin rotform och tokenisera ord till symboler och text.
Steg 3: Val av modell
Regelbaserad modell: Den enklaste metoden för flerspråkig semantisk analys är regelbaserad. Den regelbaserade algoritmen utför analysen baserat på en uppsättning förutbestämda regler programmerade av experterna.
Regeln kan ange ord eller fraser som är positiva eller negativa. Om du till exempel tar en produkt- eller tjänstrecension kan den innehålla positiva eller negativa ord som "bra", "långsam", "vänta" och "användbar". Denna metod gör det enkelt att klassificera ord, men det kan felklassificera komplicerade eller mindre frekventa ord.
Automatisk modell: Den automatiska modellen utför flerspråkig sentimentanalys utan inblandning av mänskliga moderatorer. Även om maskininlärningsmodellen är byggd med mänsklig ansträngning, kan den fungera automatiskt för att leverera korrekta resultat när den väl utvecklats.
Testdata analyseras och varje kommentar märks manuellt som positiv eller negativ. ML-modellen kommer sedan att lära av testdatan genom att jämföra den nya texten med de befintliga kommentarerna och kategorisera dem.
Steg 4: Analys och utvärdering
De regelbaserade och maskininlärningsmodellerna kan förbättras och förbättras över tid och erfarenhet. Ett lexikon med mindre ofta använda ord eller liveresultat för flerspråkiga känslor kan uppdateras för snabbare och mer exakt klassificering.
Översättningens utmaning
Räcker det inte med översättning? Faktiskt nej!
Översättning innebär att överföra text eller grupper av text från ett språk och hitta en motsvarighet på ett annat. Översättning är dock varken enkel eller effektiv.
Det beror på att människor använder språket inte bara för att kommunicera sina behov utan också för att uttrycka sina känslor. Dessutom finns det stora skillnader mellan olika språk, som engelska, hindi, mandarin och thailändska. Lägg till denna litterära mix av känslor, slang, idiom, sarkasm och emojis. Det går inte att få en korrekt översättning av texten.
Några av de största utmaningarna maskinöversättning är
- Subjektivitet
- Sammanhang
- Slang och idiom
- Sarkasm
- jämförelser
- Neutralitet
- Emojis och modern användning av ord.
Utan att korrekt förstå den avsedda innebörden av recensionerna, kommentarerna och kommunikationen angående deras produkter, priser, tjänster, funktioner och kvalitet, kommer företag inte att kunna förstå kundernas behov och åsikter.
Flerspråkig sentimentanalys är en utmanande process. Varje språk har sitt unika lexikon, syntax, morfologi och fonologi. Lägg till detta kulturen, slangen, känslor uttryckt, sarkasm och tonalitet, och du har ett utmanande pussel som behöver en effektiv AI-driven ML-lösning.
En omfattande flerspråkig datauppsättning behövs för att utveckla robust flerspråkig verktyg för sentimentanalys som kan bearbeta recensioner och ge kraftfulla insikter till företag. Shaip är marknadsledare på att tillhandahålla industrianpassade, märkta, kommenterade datauppsättningar på flera språk som hjälper till att utveckla effektiva och korrekta flerspråkiga lösningar för sentimentanalys.


