
Världen har inte varit densamma ända sedan datorer började titta på föremål och tolka dem. Från underhållande element som kan vara så enkelt som ett Snapchat-filter som producerar ett roligt skägg i ansiktet till komplexa system som autonomt upptäcker närvaron av små tumörer från skanningsrapporter, datorseende spelar en stor roll i mänsklighetens utveckling.
Men för ett otränat AI-system betyder ett visuellt prov eller en datauppsättning som matas in i det ingenting. Du kan mata en bild av en livlig Wall Street eller en bild av glass, systemet skulle inte veta vad båda är. Det beror på att de inte har lärt sig hur man klassificerar och segmenterar bilder och visuella element än.
Nu är detta en mycket komplex och tidskrävande process som kräver noggrann uppmärksamhet på detaljer och arbete. Det är här experter på datakommentarer kommer in och tillskriver eller taggar manuellt varje enskild byte med information på bilder för att säkerställa att AI-modeller enkelt lär sig de olika elementen i en visuell datauppsättning. När en dator tränar på kommenterade data skiljer den lätt ett landskap från en stadsbild, ett djur från en fågel, dryck och mat och andra komplexa klassificeringar.
Nu när vi vet detta, hur klassificerar och taggar datakommentarer bildelement? Finns det några specifika tekniker de använder? Om ja, vilka är de?
Tja, det är precis vad det här inlägget kommer att handla om – bildanmärkning typer, deras fördelar, utmaningar och användningsfall.
Typer av bildkommentarer
Bildkommentartekniker för datorseende kan klassificeras i fem huvudkategorier:
- Objektdetektering
- Linjedetektering
- Landmärke upptäckt
- segmente~~POS=TRUNC
- Bildklassificering
Objektdetektion
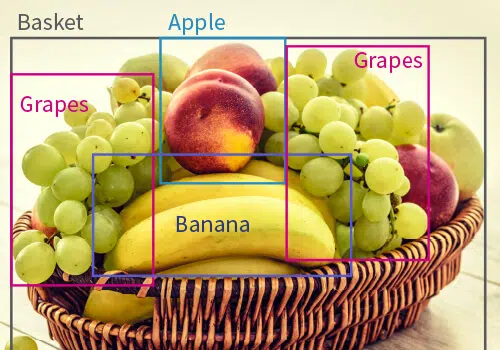 Som namnet antyder är målet med objektdetektering att hjälpa datorer och AI-modeller att identifiera olika objekt i bilder. För att specificera vilka olika objekt som är, använder dataanteckningsexperter tre framträdande tekniker:
Som namnet antyder är målet med objektdetektering att hjälpa datorer och AI-modeller att identifiera olika objekt i bilder. För att specificera vilka olika objekt som är, använder dataanteckningsexperter tre framträdande tekniker:
- 2D-avgränsningsrutor: där rektangulära rutor över olika objekt i bilder ritas och märks.
- 3D-avgränsningsrutor: där 3-dimensionella rutor ritas över föremål för att få fram djupet på föremål också.
- polygoner: där oregelbundna och unika föremål märks genom att markera kanterna på ett föremål och slutligen sammanfoga dem för att täcka formen på föremålet.
Fördelar
- Teknikerna för 2D- och 3D-begränsningsrutor är mycket enkla och objekt kan lätt märkas.
- 3D bounding boxes erbjuder fler detaljer såsom orienteringen av ett objekt, vilket saknas i 2D bound box-tekniken.
Nackdelar med objektdetektering
- 2D- och 3D-begränsningsrutor inkluderar även bakgrundspixlar som faktiskt inte är en del av ett objekt. Detta snedvrider träningen på flera sätt.
- I 3D bounding box-tekniken antar annotatorer oftast djupet av ett objekt. Detta påverkar också träningen avsevärt.
- Polygontekniken kan vara tidskrävande om ett objekt är mycket komplext.
Linjedetektering
Denna teknik används för att segmentera, kommentera eller identifiera linjer och gränser i bilder. Till exempel körfält på en stadsväg.
Fördelar
Den stora fördelen med den här tekniken är att pixlar som inte delar en gemensam ram kan upptäckas och kommenteras också. Detta är idealiskt för att kommentera rader som är korta eller de som är tilltäppta.
Nackdelar
- Om det finns flera rader blir processen mer tidskrävande.
- Överlappande linjer eller objekt kan ge vilseledande information och resultat.
Landmärke Detektion
Landmärken i datakommentarer betyder inte platser av särskilt intresse eller betydelse. De är speciella eller väsentliga punkter i en bild som behöver kommenteras. Detta kan vara ansiktsdrag, biometri eller mer. Detta är också känt som poseringsuppskattning.
Fördelar
Det är idealiskt för att träna neurala nätverk som kräver exakta koordinater för landmärken.
Nackdelar
Detta är mycket tidskrävande eftersom varje minut väsentlig punkt måste kommenteras exakt.
segmente~~POS=TRUNC
En komplex process, där en enda bild klassificeras i flera segment för identifiering av olika aspekter i dem. Detta inkluderar upptäckt av gränser, lokalisering av objekt och mer. För att ge dig en bättre uppfattning, här är en lista över framträdande segmenteringstekniker:
- Semantisk segmentering: där varje enskild pixel i en bild är kommenterad med detaljerad information. Avgörande för modeller som kräver miljökontext.
- Instanssegmentering: där varje instans av ett element i en bild är kommenterad för detaljerad information.
- Panoptisk segmentering: där detaljer från semantisk och instanssegmentering ingår och kommenteras i bilder.
Fördelar
- Dessa tekniker tar fram de finaste bitarna av information från föremål.
- De tillför mer sammanhang och värde för träningsändamål, vilket i slutändan optimerar resultaten.
Nackdelar
Dessa tekniker är arbetsintensiva och tråkiga.
Bildklassificering
 Bildklassificering innebär identifiering av element i ett objekt och klassificering av dem i specifika objektklasser. Denna teknik skiljer sig mycket från objektdetekteringstekniken. I den senare identifieras endast föremål. Till exempel kan en bild av en katt helt enkelt annoteras som ett djur.
Bildklassificering innebär identifiering av element i ett objekt och klassificering av dem i specifika objektklasser. Denna teknik skiljer sig mycket från objektdetekteringstekniken. I den senare identifieras endast föremål. Till exempel kan en bild av en katt helt enkelt annoteras som ett djur.
Men i bildklassificering klassas bilden som en katt. För bilder med flera djur detekteras varje djur och klassificeras därefter.
Fördelar
- Ger maskiner mer information om vad objekt i datauppsättningar är.
- Hjälper modeller att exakt skilja mellan djur (till exempel) eller något modellspecifikt element.
Nackdelar
Kräver mer tid för dataanteckningsexperter att noggrant identifiera och klassificera alla bildelement.
Använd fall av bildanteckningstekniker i datorseende
| Bildanteckningsteknik | Användningsfall |
|---|---|
| 2D & 3D begränsningsrutor | Idealisk för att kommentera bilder av produkter och varor för maskininlärningssystem för att uppskatta kostnader, lager och mer. |
| polygoner | På grund av deras förmåga att kommentera oregelbundna föremål och former, är de idealiska för att märka mänskliga organ i digitala bilder såsom röntgenstrålar, CT-skanningar och mer. De kan användas för att träna system för att upptäcka anomalier och deformiteter från sådana rapporter. |
| Semantisk segmentering | Används i den självkörande bilens utrymme, där varje pixel som är associerad med fordonsrörelse kan märkas exakt. Bildklassificering är tillämplig i självkörande bilar, där data från sensorer kan användas för att upptäcka och skilja mellan djur, fotgängare, vägobjekt, körfält med mera. |
| Landmärke Detektion | Används för att upptäcka och studera mänskliga känslor och för utveckling av system för ansiktsigenkänning. |
| Linjer Och Splines | Användbar i lager och tillverkningsenheter, där gränser kunde fastställas för robotar att utföra automatiserade uppgifter. |
Inslag Up
Som du ser, dator vision är extremt komplex. Det finns massor av krångligheter som måste tas om hand. Även om dessa ser skrämmande ut och låter, inkluderar ytterligare utmaningar tillgången på kvalitetsdata i rätt tid, utan fel dataanmärkning processer och arbetsflöden, annotatörernas ämnesexpertis och mer.
Som sagt, dataanteckningsföretag som t.ex Shaip gör ett enormt jobb med att leverera kvalitetsdatauppsättningar till företag som behöver dem. Under de kommande månaderna kan vi också se utveckling i detta utrymme, där maskininlärningssystem kan korrekt kommentera datauppsättningar av sig själva utan fel.


