
AI, Big Data och Machine Learning fortsätter att påverka beslutsfattare, företag, vetenskap, mediehus och en mängd olika branscher över hela världen. Rapporter tyder på att den globala adoptionshastigheten för AI för närvarande ligger på 35% i 2022 – en enorm ökning med 4 % från 2021. Ytterligare 42 % av företagen uppges undersöka de många fördelarna med AI för sin verksamhet.
Att driva de många AI-initiativen och Maskininlärning lösningar är data. AI kan bara vara lika bra som den data som matar algoritmen. Data av låg kvalitet kan resultera i resultat av låg kvalitet och felaktiga förutsägelser.
Även om det har varit mycket uppmärksamhet kring ML- och AI-lösningsutveckling, saknas medvetenheten om vad som kvalificerar sig som en kvalitetsdatauppsättning. I den här artikeln navigerar vi tidslinjen för AI-träningsdata av hög kvalitet och identifiera framtiden för AI genom en förståelse för datainsamling och utbildning.
Definition av AI-träningsdata
När man bygger en ML-lösning spelar kvantiteten och kvaliteten på utbildningsdataset roll. ML-systemet kräver inte bara stora volymer av dynamisk, opartisk och värdefull träningsdata, utan det behöver också mycket av det.
Men vad är AI-träningsdata?
AI-träningsdata är en samling märkta data som används för att träna ML-algoritmen för att göra korrekta förutsägelser. ML-systemet försöker känna igen och identifiera mönster, förstå samband mellan parametrar, fatta nödvändiga beslut och utvärdera baserat på träningsdata.
Ta exemplet med självkörande bilar till exempel. Utbildningsdataset för en självkörande ML-modell bör innehålla märkta bilder och videor av bilar, fotgängare, gatuskyltar och andra fordon.
Kort sagt, för att förbättra kvaliteten på ML-algoritmen behöver du stora mängder välstrukturerade, kommenterade och märkta träningsdata.
Vikten av kvalitetsutbildningsdata och dess utveckling
Högkvalitativ träningsdata är nyckelinput i AI- och ML-apputveckling. Data samlas in från olika källor och presenteras i en oorganiserad form som är olämplig för maskininlärningsändamål. Träningsdata av hög kvalitet – märkta, kommenterade och taggade – är alltid i ett organiserat format – perfekt för ML-träning.
Kvalitetsutbildningsdata gör det lättare för ML-systemet att känna igen objekt och klassificera dem enligt förutbestämda egenskaper. Datauppsättningen kan ge dåliga modellresultat om klassificeringen inte är korrekt.
De tidiga dagarna av AI-träningsdata
Trots att AI dominerade den nuvarande affärs- och forskningsvärlden, dominerade de första dagarna innan ML Artificiell intelligens var ganska annorlunda.
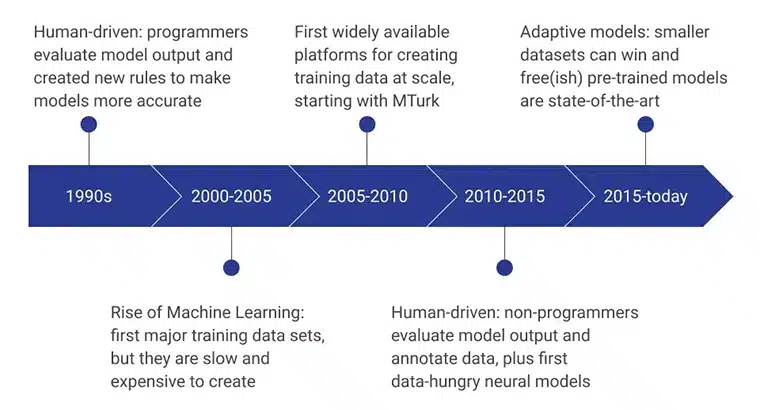
De inledande stadierna av AI-träningsdata drevs av mänskliga programmerare som utvärderade modellens produktion genom att konsekvent utarbeta nya regler som gjorde modellen mer effektiv. Under perioden 2000 – 2005 skapades den första stora datamängden, och det var en extremt långsam, resursberoende och dyr process. Det ledde till att utbildningsdatauppsättningar utvecklades i stor skala, och Amazons MTurk spelade en betydande roll i att förändra människors uppfattningar om datainsamling. Samtidigt tog mänsklig märkning och anteckning också fart.
De närmaste åren fokuserade på att icke-programmerare skapade och utvärderade datamodellerna. För närvarande ligger fokus på förtränade modeller utvecklade med hjälp av avancerade metoder för insamling av träningsdata.
Kvantitet över kvalitet
När man bedömde integriteten hos AI-träningsdatauppsättningar förr i tiden fokuserade datavetare på AI träningsdatamängd över kvalitet.
Det fanns till exempel en vanlig missuppfattning att stora databaser ger korrekta resultat. Den stora mängden data ansågs vara en bra indikator på värdet av data. Kvantitet är bara en av de primära faktorerna som bestämmer värdet av datamängden – rollen av datakvalitet erkändes.
Medvetenheten om att Datakvalitet beroende på datafullständighet, ökade tillförlitlighet, giltighet, tillgänglighet och aktualitet. Viktigast av allt var att uppgifternas lämplighet för projektet avgjorde kvaliteten på de insamlade uppgifterna.
Begränsningar av tidiga AI-system på grund av dålig träningsdata
Dålig träningsdata, tillsammans med bristen på avancerade datorsystem, var en av anledningarna till flera ouppfyllda löften om tidiga AI-system.
På grund av bristen på kvalitetsträningsdata kunde ML-lösningar inte exakt identifiera visuella mönster som stoppade utvecklingen av neural forskning. Även om många forskare identifierade löftet om talat språkigenkänning, kunde forskning eller utveckling av taligenkänningsverktyg inte förverkligas tack vare bristen på taldataset. Ett annat stort hinder för att utveckla avancerade AI-verktyg var datorernas brist på beräknings- och lagringskapacitet.
Övergången till kvalitetsutbildningsdata
Det skedde en markant förändring i medvetenheten om att datamängdens kvalitet har betydelse. För att ML-systemet ska kunna efterlikna mänsklig intelligens och beslutsfattande förmåga, måste det utvecklas med högvolym och högkvalitativ träningsdata.
Se dina ML-data som en undersökning – ju större dataprov storlek, desto bättre förutsägelse. Om provdata inte inkluderar alla variabler kanske de inte känner igen mönster eller ger felaktiga slutsatser.
Framsteg inom AI-teknik och behovet av bättre träningsdata
 Framstegen inom AI-teknik ökar behovet av utbildningsdata av hög kvalitet.
Framstegen inom AI-teknik ökar behovet av utbildningsdata av hög kvalitet.Förståelsen att bättre utbildningsdata ökar chansen för tillförlitliga ML-modeller gav upphov till bättre datainsamling, anteckningar och märkningsmetoder. Datans kvalitet och relevans påverkade direkt kvaliteten på AI-modellen.
 Framstegen inom AI-teknik ökar behovet av utbildningsdata av hög kvalitet.
Framstegen inom AI-teknik ökar behovet av utbildningsdata av hög kvalitet.Ökat fokus på datakvalitet och precision
För att ML-modellen ska börja ge korrekta resultat matas den på kvalitetsdatauppsättningar som går igenom iterativa dataraffineringssteg.
Till exempel kan en människa kunna känna igen en specifik hundras inom några dagar efter att ha blivit introducerad till rasen – genom bilder, videor eller personligen. Människor hämtar från sin erfarenhet och relaterad information för att komma ihåg och dra fram denna kunskap när det behövs. Ändå fungerar det inte lika lätt för en maskin. Maskinen måste matas med tydligt kommenterade och märkta bilder – hundratals eller tusentals – av just den rasen och andra raser för att den ska kunna göra anslutningen.
En AI-modell förutsäger resultatet genom att korrelera den information som tränas med informationen som presenteras i verkliga världen. Algoritmen görs oanvändbar om träningsdatan inte innehåller relevant information.
Vikten av olika och representativa utbildningsdata
Ökad mångfald av data ökar också kompetensen, minskar partiskhet och ökar en rättvis representation av alla scenarier. Om AI-modellen tränas med hjälp av en homogen datauppsättning kan du vara säker på att den nya applikationen endast kommer att fungera för ett specifikt syfte och tjäna en specifik population.En datauppsättning kan vara partisk mot en viss population, ras, kön, val och intellektuella åsikter, vilket kan leda till en felaktig modell.
Det är viktigt att se till att hela datainsamlingsprocessens flöde, inklusive val av ämnespool, kuration, anteckning och märkning, är tillräckligt mångsidigt, balanserat och representativt för befolkningen.
 Ökad mångfald av data ökar också kompetensen, minskar partiskhet och ökar en rättvis representation av alla scenarier. Om AI-modellen tränas med hjälp av en homogen datauppsättning kan du vara säker på att den nya applikationen endast kommer att fungera för ett specifikt syfte och tjäna en specifik population.
Ökad mångfald av data ökar också kompetensen, minskar partiskhet och ökar en rättvis representation av alla scenarier. Om AI-modellen tränas med hjälp av en homogen datauppsättning kan du vara säker på att den nya applikationen endast kommer att fungera för ett specifikt syfte och tjäna en specifik population.Framtiden för AI-utbildningsdata
Den framtida framgången för AI-modeller beror på kvaliteten och kvantiteten av träningsdata som används för att träna ML-algoritmerna. Det är viktigt att inse att detta förhållande mellan datakvalitet och kvantitet är uppgiftsspecifikt och inte har något definitivt svar.
I slutändan definieras lämpligheten hos en träningsdatauppsättning av dess förmåga att prestera tillförlitligt bra för det syfte den är byggd.
Framsteg inom datainsamling och anteckningstekniker
Eftersom ML är känsligt för matad data är det viktigt att effektivisera datainsamling och anteckningspolicyer. Fel i datainsamling, kuration, felaktig framställning, ofullständiga mätningar, felaktigt innehåll, dataduplicering och felaktiga mätningar bidrar till otillräcklig datakvalitet.
Automatiserad datainsamling genom datautvinning, webbskrapning och dataextraktion banar väg för snabbare datagenerering. Dessutom fungerar förpackade datamängder som en snabbfixningsteknik för datainsamling.
Crowdsourcing är en annan banbrytande metod för datainsamling. Även om sanningshalten i uppgifterna inte kan garanteras, är den ett utmärkt verktyg för att samla in offentlig bild. Slutligen specialiserad datainsamling experter tillhandahåller också data som hämtas för specifika ändamål.
Ökad betoning på etiska överväganden i träningsdata
Med de snabba framstegen inom AI har flera etiska frågor dykt upp, särskilt när det gäller insamling av träningsdata. Några etiska överväganden vid insamling av utbildningsdata inkluderar informerat samtycke, transparens, partiskhet och datasekretess.Eftersom data nu omfattar allt från ansiktsbilder, fingeravtryck, röstinspelningar och andra kritiska biometriska data, blir det avgörande att se till att rättsliga och etiska rutiner följs för att undvika dyra stämningar och skada på ryktet.
Potentialen för ännu bättre kvalitet och mångsidig träningsdata i framtiden
Det finns en enorm potential för högkvalitativa och varierande utbildningsdata i framtiden. Tack vare medvetenheten om datakvalitet och tillgängligheten av dataleverantörer som tillgodoser kvalitetskraven för AI-lösningar.
Nuvarande dataleverantörer är skickliga på att använda banbrytande teknik för att etiskt och juridiskt skaffa enorma mängder olika datauppsättningar. De har också interna team för att märka, kommentera och presentera data anpassade för olika ML-projekt.
 Med de snabba framstegen inom AI har flera etiska frågor dykt upp, särskilt när det gäller insamling av träningsdata. Några etiska överväganden vid insamling av utbildningsdata inkluderar informerat samtycke, transparens, partiskhet och datasekretess.
Med de snabba framstegen inom AI har flera etiska frågor dykt upp, särskilt när det gäller insamling av träningsdata. Några etiska överväganden vid insamling av utbildningsdata inkluderar informerat samtycke, transparens, partiskhet och datasekretess.Slutsats
Det är viktigt att samarbeta med pålitliga leverantörer med en akut förståelse för data och kvalitet utveckla avancerade AI-modeller. Shaip är det främsta annoteringsföretaget som är skickligt på att tillhandahålla skräddarsydda datalösningar som möter dina AI-projektbehov och mål. Samarbeta med oss och utforska kompetensen, engagemanget och samarbetet vi tar till bordet.


