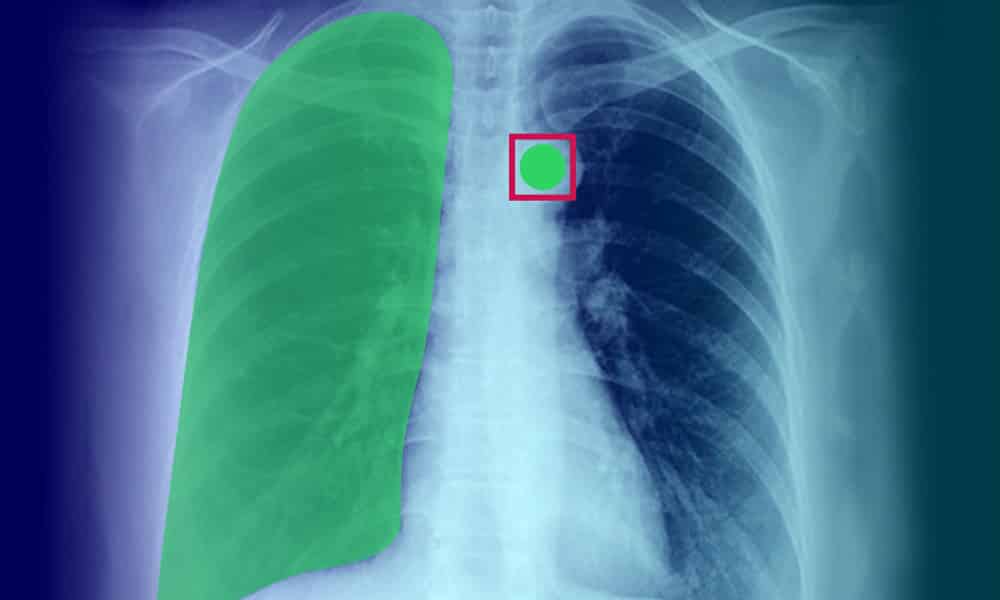
En robust AI-baserad lösning är byggd på data – inte vilken data som helst utan högkvalitativ, korrekt kommenterad data. Endast de bästa och mest förfinade data kan driva ditt AI-projekt, och denna datarenhet kommer att ha en enorm inverkan på projektets resultat.
Vi har ofta kallat data för bränslet för AI-projekt, men inte vilken data som helst duger. Om du behöver raketbränsle för att hjälpa ditt projekt att uppnå lyft, kan du inte lägga råolja i tanken. Istället måste data (som bränsle) noggrant förfinas för att säkerställa att endast information av högsta kvalitet driver ditt projekt. Den förfiningsprocessen kallas dataanteckning, och det finns en hel del ihållande missuppfattningar om det.
Definiera utbildningsdatakvalitet i annotering
Vi vet att datakvaliteten gör stor skillnad för resultatet av AI-projektet. Några av de bästa och mest högpresterande ML-modellerna har baserats på detaljerade och noggrant märkta datamängder.
Men exakt hur definierar vi kvalitet i en kommentar?
När vi pratar om dataanmärkning kvalitet, noggrannhet, tillförlitlighet och konsekvens spelar roll. En datamängd sägs vara korrekt om den matchar grundsanningen och verklig information.
Konsistens av data hänvisar till nivån av noggrannhet som upprätthålls i hela datamängden. Kvaliteten på en datauppsättning bestäms dock mer exakt av typen av projekt, dess unika krav och det önskade resultatet. Därför bör detta vara kriterierna för att bestämma datamärkning och anteckningskvalitet.
Varför är det viktigt att definiera datakvalitet?
Det är viktigt att definiera datakvalitet eftersom det fungerar som en övergripande faktor som avgör kvaliteten på projektet och resultatet.
- Data av dålig kvalitet kan påverka produktens och affärsstrategierna.
- Ett maskininlärningssystem är lika bra som kvaliteten på data det tränas på.
- Data av god kvalitet eliminerar omarbetning och kostnader förknippade med det.
- Det hjälper företag att fatta välgrundade projektbeslut och följa regelverk.
Hur mäter vi utbildningsdatakvalitet vid märkning?

Det finns flera metoder för att mäta utbildningsdatakvalitet, och de flesta av dem börjar med att först skapa en konkret dataanteckningsriktlinje. Några av metoderna inkluderar:
Riktmärken fastställda av experter
Kvalitetsriktmärken eller guldstandardkommentar metoder är de enklaste och mest prisvärda kvalitetssäkringsalternativen som fungerar som en referenspunkt för att mäta kvaliteten på projektets resultat. Den mäter dataanteckningarna mot det riktmärke som experterna fastställt.
Cronbachs alfatest
Cronbachs alfatest bestämmer korrelationen eller överensstämmelsen mellan datauppsättningsobjekt. Etikettens tillförlitlighet och större noggrannhet kan mätas utifrån forskningen.
Konsensusmätning
Konsensusmätning avgör graden av överensstämmelse mellan maskin- eller mänskliga annotatorer. Konsensus bör vanligtvis nås för varje punkt och bör medlingsas i händelse av oenighet.
Panelgranskning
En expertpanel avgör vanligtvis etikettens noggrannhet genom att granska dataetiketter. Ibland tas vanligtvis en definierad del av dataetiketter som ett prov för att bestämma noggrannheten.
Efter en genomgång av Utbildningsdata Kvalitet
Företagen som tar sig an AI-projekt har fullt upp i kraften i automatisering, varför många fortsätter att tro att automatisk annotering-driven av AI kommer att bli snabbare och mer exakt än att kommentera manuellt. För tillfället är verkligheten att det tar människor att identifiera och klassificera data eftersom noggrannhet är så viktig. De ytterligare fel som skapas genom automatisk märkning kommer att kräva ytterligare iterationer för att förbättra algoritmens noggrannhet, vilket medför att alla tidsbesparingar förnekas.
En annan missuppfattning - och en som sannolikt bidrar till antagandet av automatisk annotering - är att små fel inte påverkar resultatet särskilt mycket. Även de minsta felen kan ge betydande felaktigheter på grund av ett fenomen som kallas AI -drift, där inkonsekvenser i inmatningsdata leder en algoritm i en riktning som programmerare aldrig har tänkt sig.
Kvaliteten på utbildningsdata – aspekterna av noggrannhet och konsekvens – granskas konsekvent för att möta de unika kraven i projekten. En genomgång av träningsdata utförs vanligtvis med två olika metoder –
Automatiska annoterade tekniker
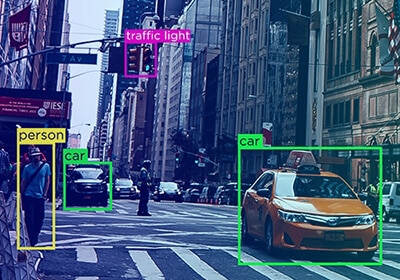 Processen för automatisk anteckningsgranskning säkerställer att feedback återförs i systemet och förhindrar felaktigheter så att annotatorer kan förbättra sina processer.
Processen för automatisk anteckningsgranskning säkerställer att feedback återförs i systemet och förhindrar felaktigheter så att annotatorer kan förbättra sina processer.
Automatisk annotering som drivs av artificiell intelligens är korrekt och snabbare. Automatisk anteckning minskar den tid manuella kvalitetskontrollanter spenderar på att granska, vilket gör att de kan lägga mer tid på komplexa och kritiska fel i datamängden. Automatisk anteckning kan också hjälpa till att upptäcka ogiltiga svar, upprepningar och felaktiga anteckningar.
Manuellt via datavetenskapsexperter
Dataforskare granskar också datakommentarer för att säkerställa noggrannhet och tillförlitlighet i datamängden.
Små fel och felaktigheter i anteckningar kan avsevärt påverka resultatet av projektet. Och dessa fel kanske inte upptäcks av verktygen för automatisk anteckningsgranskning. Dataforskare gör provkvalitetstestning från olika batchstorlekar för att upptäcka datainkonsekvenser och oavsiktliga fel i datasetet.
Bakom varje AI-rubrik ligger en kommentarprocess, och Shaip kan hjälpa till att göra det smärtfritt
Undvika AI-projektfällor
Många organisationer plågas av brist på interna anteckningsresurser. Datavetare och ingenjörer är mycket efterfrågade, och att anställa tillräckligt många av dessa proffs för att ta sig an ett AI-projekt innebär att skriva en check som är utom räckhåll för de flesta företag. Istället för att välja ett budgetalternativ (som crowdsourcing-kommentarer) som så småningom kommer tillbaka för att förfölja dig, överväg att lägga ut dina annoteringsbehov på entreprenad till en erfaren extern partner. Outsourcing säkerställer en hög grad av noggrannhet samtidigt som de minskar flaskhalsarna för anställning, utbildning och ledning som uppstår när du försöker sätta ihop ett internt team.
När du lägger ut dina annoteringsbehov specifikt med Shaip använder du en kraftfull kraft som kan påskynda ditt AI-initiativ utan de genvägar som äventyrar alla viktiga resultat. Vi erbjuder en fullt förvaltad arbetskraft, vilket innebär att du kan få mycket större noggrannhet än vad du skulle uppnå genom crowdsourcing -anmärkningsinsatser. Förhandsinvesteringarna kan vara högre, men det kommer att löna sig under utvecklingsprocessen när färre iterationer är nödvändiga för att uppnå önskat resultat.
Våra datatjänster täcker också hela processen, inklusive inköp, vilket är en förmåga som de flesta andra märkningsleverantörer inte kan erbjuda. Med vår erfarenhet kan du snabbt och enkelt skaffa stora mängder geografiskt varierande data av hög kvalitet som har avidentifierats och uppfyller alla relevanta föreskrifter. När du lagrar dessa data i vår molnbaserade plattform får du också tillgång till beprövade verktyg och arbetsflöden som ökar projektets totala effektivitet och hjälper dig att utvecklas snabbare än du trodde var möjligt.
Och slutligen vår egna branschexperter förstå dina unika behov. Oavsett om du bygger en chatbot eller arbetar med att använda teknik för ansiktsigenkänning för att förbättra vården, har vi varit där och kan hjälpa till att utveckla riktlinjer som säkerställer att anteckningsprocessen uppnår de mål som anges för ditt projekt.
På Shaip är vi inte bara glada över den nya eran av AI. Vi hjälper det på otroliga sätt, och vår erfarenhet har hjälpt oss att få otaliga framgångsrika projekt från marken. Kontakta oss för att se vad vi kan göra för din egen implementering begära en demo i dag.