
Artificiell intelligens främjar mänskliga interaktioner med datorsystem, medan maskininlärning låter dessa maskiner lära sig att efterlikna mänsklig intelligens genom varje interaktion. Men vad driver dessa mycket avancerade ML- och AI-verktyg? Dataanteckning.
Data är råmaterialet som driver ML-algoritmerna – ju mer data du använder, desto bättre blir AI-produkten. Även om det är ytterst viktigt att ha tillgång till stora mängder data, är det lika viktigt att se till att de är korrekt kommenterade för att ge genomförbara resultat. Datakommentarer är datakraftverket bakom avancerad, pålitlig och exakt ML-algoritmisk prestanda.
Rollen för dataanteckning i AI-träning
Datakommentarer spelar en nyckelroll i ML-träning och den övergripande framgången för AI-projekt. Det hjälper till att identifiera specifika bilder, data, mål och videor och etiketterar dem för att göra det lättare för maskinen att identifiera mönster och klassificera data. Det är en mänskligt ledd uppgift som tränar ML-modellen för att göra korrekta förutsägelser.
Om dataanteckningen inte utförs korrekt kan ML-algoritmen inte enkelt associera attribut med objekt.
Vikten av annoterade träningsdata för AI-system
Datakommentarer möjliggör korrekt funktion av ML-modeller. Det finns en obestridlig koppling mellan noggrannheten och precisionen i datakommentarer och framgången för AI-projektet.
Det globala AI-marknadsvärdet, beräknat till 119 miljarder dollar 2022, förutspås nå $ 1,597 miljard vid 2030, som växer med en CAGR på 38 % under perioden. Medan hela AI-projektet går igenom flera kritiska steg, är dataanteckningsstadiet där ditt projekt befinner sig i det viktigaste skedet.
Att samla in data för datas skull kommer inte att hjälpa ditt projekt mycket. Du behöver enorma mängder av högkvalitativ, relevant data för att genomföra ditt AI-projekt framgångsrikt. Ungefär 80 % av din tid i ML-projektutveckling ägnas åt datarelaterade uppgifter, såsom märkning, skrubbning, aggregering, identifiering, förstärkning och anteckning.
Datakommentarer är ett område där människor har en fördel framför datorer eftersom vi har den medfödda förmågan att dechiffrera avsikter, vada genom tvetydighet och klassificera osäker information.
Varför är dataanteckning viktig?
Värdet och trovärdigheten för din artificiella intelligenslösning beror till stor del på kvaliteten på datainmatningen som används för modellträning.
En maskin kan inte bearbeta bilder som vi gör; de behöver tränas för att känna igen mönster genom träning. Eftersom maskininlärningsmodeller tillgodoser ett brett spektrum av applikationer – kritiska lösningar som sjukvård och autonoma fordon – där alla fel i datakommentarer kan få farliga återverkningar.
Datakommentarer säkerställer att din AI-lösning fungerar till fullo. Att träna en ML-modell för att korrekt tolka sin miljö genom mönster och korrelationer, göra förutsägelser och vidta nödvändiga åtgärder kräver högt kategoriserade och kommenterade träningsdata. Annoteringen visar ML-modellen den nödvändiga förutsägelsen genom att tagga, transkribera och märka kritiska funktioner i datasetet.
Övervakad inlärning
Innan vi gräver djupare i datakommentarer, låt oss reda ut datakommentarer genom övervakat och oövervakat lärande.
En underkategori av maskininlärning övervakad maskininlärning indikerar AI-modellträning med hjälp av en väl märkt dataset. I en övervakad inlärningsmetod är vissa data redan korrekt taggade och kommenterade. ML-modellen, när den exponeras för ny data, använder sig av träningsdata för att komma fram till en korrekt förutsägelse baserat på märkta data.
Till exempel tränas ML-modellen på ett skåp fullt av olika typer av kläder. Det första steget i träningen skulle vara att träna modellen med olika typer av kläder med hjälp av egenskaperna och egenskaperna för varje tyg. Efter utbildningen kommer maskinen att kunna identifiera separata klädesplagg genom att tillämpa sina tidigare kunskaper eller utbildning. Övervakat lärande kan kategoriseras i klassificering (baserat på kategori) och regression (baserat på verkligt värde).
Hur datakommentarer påverkar prestanda hos AI-system
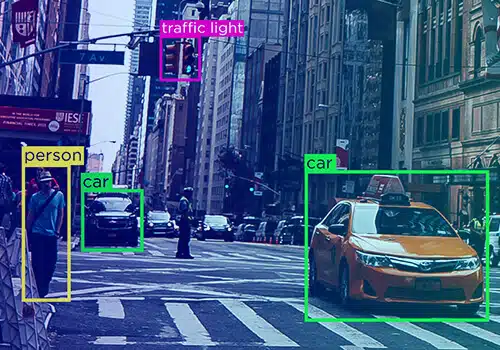 Data är aldrig en enda enhet – den tar olika former – text, video och bild. Onödigt att säga att datakommentarer finns i olika former.
Data är aldrig en enda enhet – den tar olika former – text, video och bild. Onödigt att säga att datakommentarer finns i olika former.
För att maskinen ska förstå och exakt identifiera olika entiteter är det viktigt att betona kvaliteten på Named Entity Tagging. Ett misstag i taggning och anteckning, och ML kunde inte skilja mellan Amazon – e-handelsbutiken, floden eller en papegoja.
Dessutom hjälper datakommentarer maskiner att känna igen subtila avsikter – en kvalitet som kommer naturligt för människor. Vi kommunicerar på olika sätt, och människor förstår både uttryckliga tankar och underförstådda budskap. Till exempel kan svar eller recensioner på sociala medier vara både positiva och negativa, och ML bör kunna förstå båda. 'Fantastiskt ställe. Kommer att besöka igen.' Det är en positiv fras medan "Vilken fantastisk plats det brukade vara! Vi brukade älska det här stället!' är negativ, och mänsklig kommentar kan göra denna process mycket lättare.

Utmaningar i datakommentarer och hur man kan övervinna dem
Två huvudutmaningar i datakommentarer är kostnad och noggrannhet.
Behovet av mycket exakta data: AI- och ML-projektens öde beror på kvaliteten på kommenterade data. ML- och AI-modellerna måste konsekvent matas med välklassificerade data som kan träna modellen att känna igen korrelationen mellan variabler.
Behovet av stora mängder data: Alla ML- och AI-modeller trivs med stora datamängder – ett enda ML-projekt behöver minst tusentals märkta objekt.
Behovet av resurser: AI-projekt är resursberoende, både vad gäller kostnad, tid och personalstyrka. Utan endera av dessa kan kvaliteten på ditt dataanteckningsprojekt gå åt helvete.
[Läs även: Videokommentar för maskininlärning ]
Bästa metoder för datakommentarer
Värdet av datakommentarer är uppenbart i dess inverkan på resultatet av AI-projektet. Om datamängden du tränar dina ML-modeller på är fylld av inkonsekvenser, partisk, obalanserad eller korrupt, kan din AI-lösning vara ett misslyckande. Dessutom, om etiketterna är felaktiga och anteckningen är inkonsekvent, kommer AI-lösningen också att åstadkomma felaktiga förutsägelser. Så, vilka är de bästa metoderna för datakommentarer?
Tips för effektiv och effektiv dataanteckning
- Se till att dataetiketterna du skapar är specifika och överensstämmande med projektets behov och ändå tillräckligt allmänna för att tillgodose alla möjliga variationer.
- Annotera stora mängder data som behövs för att träna maskininlärningsmodellen. Ju mer data du kommenterar, desto bättre blir resultatet av modellträningen.
- Riktlinjer för datakommentarer går långt när det gäller att etablera kvalitetsstandarder och säkerställa konsistens genom hela projektet och mellan flera annotatorer.
- Eftersom datakommentarer kan vara kostsamma och arbetskraftsberoende, är det meningsfullt att kolla in förmärkta datauppsättningar från tjänsteleverantörer.
- För att hjälpa till med korrekta datakommentarer och utbildning, ta in effektiviteten hos människa-i-slingan för att skapa mångfald och hantera kritiska fall tillsammans med funktionerna hos annoteringsprogramvara.
- Prioritera kvalitet genom att testa annotatorerna för kvalitetsefterlevnad, noggrannhet och konsekvens.
Vikten av kvalitetskontroll i anteckningsprocessen
 Kvalitetsdatakommentarer är livsnerven i högpresterande AI-lösningar. Välkommenterade datauppsättningar hjälper AI-system att prestera oklanderligt bra, även i en kaotisk miljö. På samma sätt är det omvända också lika sant. En datauppsättning full av felaktigheter i annoteringarna kommer att skapa inkonsekventa lösningar.
Kvalitetsdatakommentarer är livsnerven i högpresterande AI-lösningar. Välkommenterade datauppsättningar hjälper AI-system att prestera oklanderligt bra, även i en kaotisk miljö. På samma sätt är det omvända också lika sant. En datauppsättning full av felaktigheter i annoteringarna kommer att skapa inkonsekventa lösningar.
Så kvalitetskontroll i bild-, videomärkningen och anteckningsprocessen spelar en viktig roll för AI-resultatet. Att upprätthålla kvalitetskontrollstandarder under hela anteckningsprocessen är dock en utmaning för små och stora företag. Beroendet av olika typer av anteckningsverktyg och olika anteckningsarbetare kan vara svårt att bedöma och upprätthålla kvalitetskonsistens.
Det är svårt att upprätthålla kvaliteten på annotatorer för distribuerade eller distansarbetande data, särskilt för dem som inte känner till de standarder som krävs. Dessutom kan felsökning eller felkorrigering ta tid eftersom det måste identifieras över en distribuerad arbetsstyrka.
Lösningen skulle vara att utbilda annotatorerna, involvera en handledare eller låta flera dataannotatorer titta in och granska kamrater för att se om datauppsättningskommentarer är korrekta. Slutligen, regelbundet testa annotatorerna på deras kunskap om standarderna.
Annotatorernas roll och hur man väljer rätt annotatorer för din data
Mänskliga kommentatorer har nyckeln till ett framgångsrikt AI-projekt. Dataannotatorer säkerställer att data är korrekt, konsekvent och tillförlitligt kommenterade eftersom de kan ge sammanhang, förstå avsikter och lägga grunden för grundsanningar i data.
Vissa data kommenteras artificiellt eller automatiskt med hjälp av automationslösningar med en rimlig grad av tillförlitlighet. Du kan till exempel ladda ner hundratusentals bilder av hus från Google och göra dem som ett dataset. Men datauppsättningens noggrannhet kan endast bestämmas på ett tillförlitligt sätt efter att modellen startar sin prestanda.
Automatiserad automatisering kan göra saken enklare och snabbare, men onekligen mindre exakt. På baksidan kan en mänsklig kommentator vara långsammare och dyrare, men de är mer exakta.
Annotatorer för mänskliga data kan kommentera och klassificera data baserat på deras ämnesexpertis, medfödda kunskap och specifika utbildning. Dataannotatorer skapar noggrannhet, precision och konsekvens.
[Läs även: En nybörjarguide till datakommentarer: tips och bästa praxis ]
Slutsats
För att skapa ett högpresterande AI-projekt behöver du högkvalitativa annoterade träningsdata. Även om det kan vara tidskrävande och resurskrävande att samla in välkommenterade data konsekvent – även för stora företag – ligger lösningen i att söka tjänster från etablerade tjänsteleverantörer för datakommentarer som Shaip. På Shaip hjälper vi dig att skala dina AI-förmågor genom våra specialisttjänster för datakommentarer genom att möta marknadens och kundernas efterfrågan.


