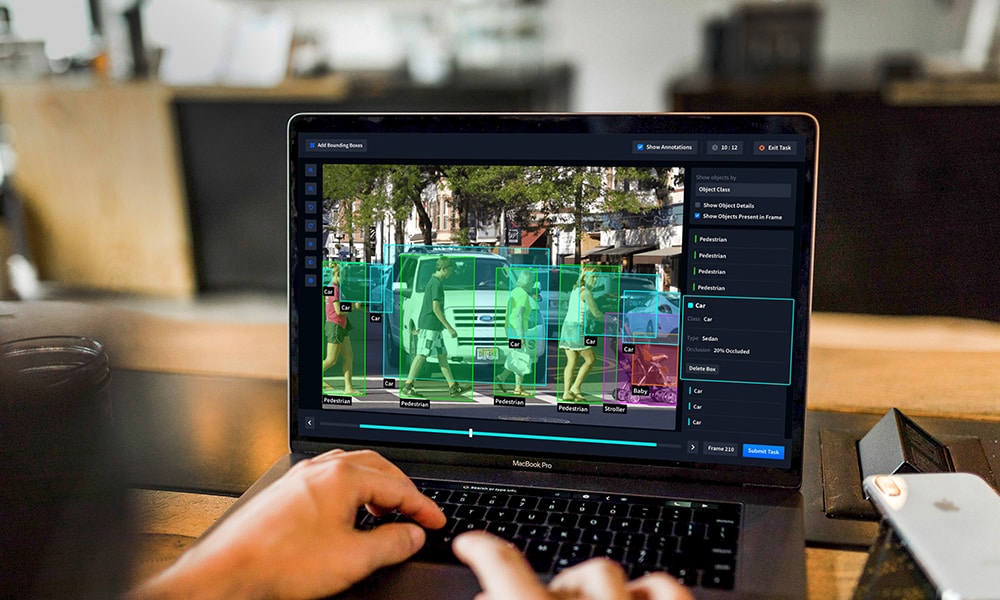
I en värld där företag stöter mot varandra för att vara de första att omvandla sina affärsmetoder genom att tillämpa lösningar med artificiell intelligens, verkar datamärkning vara den enda uppgiften alla börjar snubbla på. Kanske beror det på att kvaliteten på data du tränar dina AI-modeller på avgör deras noggrannhet och framgång.
Datamärkning eller datakommentarer är aldrig en engångshändelse. Det är en kontinuerlig process. Det finns ingen avgörande punkt där du kanske tror att du har tränat tillräckligt eller att dina AI-modeller är korrekta när det gäller att uppnå resultat.
Men var går AI:s löfte om att utnyttja nya möjligheter fel? Ibland under datamärkningsprocessen.
En av de största smärtpunkterna för företag som införlivar AI-lösningar är datakommentarer. Så låt oss ta en titt på de 5 bästa datamärkningsfelen att undvika.
Topp 5 datamärkningsfel att undvika
Samlar inte in tillräckligt med data för projektet
Data är väsentligt, men det bör vara relevant för dina projektmål. För att modellen ska ge korrekta resultat bör data den tränas på märkas, kvalitetskontrolleras för att säkerställa noggrannheten.
Om du vill utveckla en fungerande, pålitlig AI-lösning måste du mata den med stora mängder relevanta data av hög kvalitet. Och du måste hela tiden mata in dessa data till dina maskininlärningsmodeller så att de kan förstå och korrelera olika delar av information du tillhandahåller.
Uppenbarligen, ju större datamängd du använder, desto bättre blir förutsägelserna.
En fallgrop i datamärkningsprocessen är att samla in väldigt lite data för mindre vanliga variabler. När du märker bilder baserat på en allmänt tillgänglig variabel i rådokumenten tränar du inte din AI-modell för djupinlärning på andra mindre vanliga variabler.
Modeller för djupinlärning kräver tusentals databitar för att modellen ska fungera någorlunda bra. Till exempel, när man tränar en AI-baserad robotarm för att manövrera komplexa maskiner, kan varje liten variation i jobbet kräva ytterligare en grupp träningsdata. Men att samla in sådan data kan vara dyrt och ibland rent omöjligt och svårt att kommentera för alla företag.
Validerar inte datakvalitet
Även om det är en sak att ha data, är det också viktigt att validera de datamängder du använder för att säkerställa att de håller hög kvalitet. Men företag tycker att det är utmanande att skaffa kvalitetsdatauppsättningar. I allmänhet finns det två grundläggande typer av datamängder - subjektiva och objektiva.
 Vid märkning av datamängder spelar etikettörens subjektiva sanning in. Till exempel kan deras erfarenhet, språk, kulturella tolkningar, geografi och mer påverka deras tolkning av data. Alltid kommer varje etikettgivare att ge ett annat svar baserat på sina egna fördomar. Men subjektiv data har inget "rätt eller fel svar - det är därför arbetskraften måste ha tydliga standarder och riktlinjer när de märker bilder och annan data.
Vid märkning av datamängder spelar etikettörens subjektiva sanning in. Till exempel kan deras erfarenhet, språk, kulturella tolkningar, geografi och mer påverka deras tolkning av data. Alltid kommer varje etikettgivare att ge ett annat svar baserat på sina egna fördomar. Men subjektiv data har inget "rätt eller fel svar - det är därför arbetskraften måste ha tydliga standarder och riktlinjer när de märker bilder och annan data.Utmaningen med objektiva data är risken för att etikettören inte har domänerfarenhet eller kunskap för att identifiera de korrekta svaren. Det är omöjligt att helt göra sig av med mänskliga fel, så det blir viktigt att ha standarder och en återkopplingsmetod med sluten slinga.
 Vid märkning av datamängder spelar etikettörens subjektiva sanning in. Till exempel kan deras erfarenhet, språk, kulturella tolkningar, geografi och mer påverka deras tolkning av data. Alltid kommer varje etikettgivare att ge ett annat svar baserat på sina egna fördomar. Men subjektiv data har inget "rätt eller fel svar - det är därför arbetskraften måste ha tydliga standarder och riktlinjer när de märker bilder och annan data.
Vid märkning av datamängder spelar etikettörens subjektiva sanning in. Till exempel kan deras erfarenhet, språk, kulturella tolkningar, geografi och mer påverka deras tolkning av data. Alltid kommer varje etikettgivare att ge ett annat svar baserat på sina egna fördomar. Men subjektiv data har inget "rätt eller fel svar - det är därför arbetskraften måste ha tydliga standarder och riktlinjer när de märker bilder och annan data.
Fokuserar inte på Workforce Management
Maskininlärningsmodeller är beroende av stora datamängder av olika typer så att varje scenario tillgodoses. Men framgångsrik bildkommentar kommer med sina egna utmaningar för personalhantering.
En stor fråga är att hantera en stor personalstyrka som manuellt kan bearbeta betydande ostrukturerade datamängder. Nästa är att upprätthålla högkvalitativa standarder för hela personalstyrkan. Många problem kan beskäras under dataanteckningsprojekt.
Några är:
- Behovet av att utbilda nya etikettörer i att använda annoteringsverktyg
- Dokumentera instruktioner i kodboken
- Se till att kodboken följs av alla teammedlemmar
- Definiera arbetsflödet – fördela vem som gör vad baserat på deras förmåga
- Korskontrollera och lösa tekniska problem
- Säkerställa kvalitet och validering av datamängder
- Ger smidigt samarbete mellan etiketteringsteam
- Minimera etikettförspänning
För att vara säker på att du klarar den här utmaningen bör du förbättra dina färdigheter och förmågor i arbetsstyrkan.
Att inte välja rätt datamärkningsverktyg
Marknaden för dataanteckningsverktygens storlek var över $ 1 miljarder 2020, och detta antal förväntas växa med mer än 30 % CAGR år 2027. Den enorma tillväxten av verktyg för datamärkning är att det förändrar resultatet av AI och maskininlärning.
De verktygstekniker som används varierar från en datauppsättning till en annan. Vi har märkt att de flesta organisationer börjar den djupa inlärningsprocessen genom att fokusera på att utveckla interna märkningsverktyg. Men mycket snart inser de att när anteckningsbehoven börjar växa kan deras verktyg inte hålla jämna steg. Att utveckla interna verktyg är dessutom dyrt, tidskrävande och praktiskt taget onödigt.
Istället för att gå det konservativa sättet med manuell märkning eller investera i att utveckla anpassade märkningsverktyg är det smart att köpa enheter från en tredje part. Med den här metoden är allt du behöver göra att välja rätt verktyg baserat på ditt behov, de tjänster som tillhandahålls och skalbarhet.
Följer inte riktlinjerna för datasäkerhet
Efterlevnad av datasäkerhet kommer att se en betydande ökning snart när fler företag samlar in stora uppsättningar av ostrukturerad data. CCPA, DPA och GDPR är några av de internationella standarder för efterlevnad av datasäkerhet som används av företag.
Strävan efter säkerhetsefterlevnad håller på att bli accepterad eftersom när det kommer till märkning av ostrukturerad data, finns det instanser av personuppgifter på bilderna. Förutom att skydda individernas integritet är det också viktigt att se till att uppgifterna är säkrade. Företagen måste se till att arbetarna, utan säkerhetsgodkännande, inte har tillgång till dessa datamängder och inte kan överföra eller manipulera dem i någon form.Säkerhetsefterlevnad blir en central smärtpunkt när det gäller att lägga ut märkningsuppgifter på entreprenad till tredjepartsleverantörer. Datasäkerhet ökar komplexiteten i projektet, och leverantörer av märkningstjänster måste följa verksamhetens regler.
 Strävan efter säkerhetsefterlevnad håller på att bli accepterad eftersom när det kommer till märkning av ostrukturerad data, finns det instanser av personuppgifter på bilderna. Förutom att skydda individernas integritet är det också viktigt att se till att uppgifterna är säkrade. Företagen måste se till att arbetarna, utan säkerhetsgodkännande, inte har tillgång till dessa datamängder och inte kan överföra eller manipulera dem i någon form.
Strävan efter säkerhetsefterlevnad håller på att bli accepterad eftersom när det kommer till märkning av ostrukturerad data, finns det instanser av personuppgifter på bilderna. Förutom att skydda individernas integritet är det också viktigt att se till att uppgifterna är säkrade. Företagen måste se till att arbetarna, utan säkerhetsgodkännande, inte har tillgång till dessa datamängder och inte kan överföra eller manipulera dem i någon form.Så, väntar ditt nästa stora AI-projekt på rätt datamärkningstjänst?
Vi tror att framgången för alla AI-projekt beror på de datauppsättningar vi matar in i maskininlärningsalgoritmen. Och om AI-projektet förväntas ge korrekta resultat och förutsägelser, är datakommentarer och märkning av största vikt. Förbi outsourca dina dataanteckningsuppgifter, försäkrar vi dig om att du effektivt kan lösa dessa utmaningar.
Med vårt fokus på att konsekvent upprätthålla högkvalitativa datamängder, erbjuda återkoppling i sluten krets och hantera personalstyrkan effektivt, kommer du att kunna leverera förstklassiga AI-projekt som ger en högre nivå av noggrannhet.
[Läs även: Intern eller outsourcad datakommentar – vilket ger bättre AI-resultat?]